

Recreating Nanite: Raytracing

Alternative title: “Going further than Nanite: Raytracing”, but that might be a bit pretentious.
It’s been a while, I’ve spent a month trying to improve the performance and rendering quality of my engine for the GP Direct!  Carrot is visible at 12:17, but don’t hesitate to look at all the submissions!
Carrot is visible at 12:17, but don’t hesitate to look at all the submissions!
Anyway, turns out raytracing and virtual geometry don’t really want to work together.
- Introduction
- In theory
- In practice
- Building vs copying BLASes
- Optimizing the first frame
- Optimizing the next frames
- Conclusion
- Bonus: small rant about Vulkan Acceleration Structures
Firefox’s reader mode tells me that this article has a 50 to 60 minutes of read time. So don’t hesitate to take breaks and grab your favorite hot beverage ☕.
Introduction
If you are reading this article, you are probably aware that I am attempting my own implementation of virtual geometry in my engine.
My engine Carrot only supports raytracing for lighting, no shadowmaps, no baked global illumination, just bruteforce raytracing. Therefore, I needed a way to make models that use virtual geometry compatible with raytracing.
This article will explain how I managed to reach this goal. The article will start with a brief explanation of the subject, and then will explain the steps I had to take to make it work, from the asset processing, to the actual raytracing on the GPU.
The problem
For a given view point, you need something that can represent the scene, for the purpose of tracing rays: an acceleration structure (AS). While I am going to talk a lot about Vulkan acceleration structures in this article, here this should be understood as a generic AS, not necessarily a Vulkan hardware-supported AS.
With regular rasterization and LODs, this is “trivial”: select your LODs based on the camera’s positions, build an AS for the entire scene (Top Level AS, or TLAS) based on the geometries of the selected LODs (Bottom Level AS, or BLAS), and off you go.

Acceleration structures, from Vulkan documentation: Acceleration Structures
With virtual geometry, except for LOD 0 which is the original model, there is no such thing as “LOD 1,2,3”: some parts of the model may not be simplifiable to that level. This means you cannot just rely on the position of the model and the camera to find a LOD index, and raytrace that. Furthermore, some parts of the model are rendering in LOD 0, while some other parts may be rendered with a low fidelity version. You need a method that can take into account the fact that your model is made up of lots of triangle clusters.
You could create a mesh from clusters based on some metric, and rebuild the BLAS with the clusters making it up each frame. However, this is super slow (at least in 2024) and wasteful, so this is not really doable for realtime graphics. Updating a BLAS instead of building it is possible, but if only vertex positions have changed, which is not the case here.
An alternative would be to have a BLAS per triangle. Let’s just say you are going to run out of VRAM way before you can measure the performance.
How others do it
Before attempting my own implementation, I took a very quick look at what is done “in the wild”:
- Intel creates a custom BVH format from the original model and raytraces it.
- According to the article above, Unreal Engine builds a low detail version of the model and raytraces that.
- Carrot, before this article, used LOD 0 and raytraced it. This is more or less fine for visual quality, but this eats up a lot of VRAM. Also, I want to implement streaming in the future, so keeping LOD 0 always loaded would defeat the point, hence this article.
- Traverse Research seems to do something close to what this article will explain, but it is just a small sentence here:
Since our framework heavily relies on raytracing, we need to generate bottom level acceleration structures (BLASes) to be able to ray-trace the mesh, so we need to find a balance between triangle count, memory overhead and runtime performance.
While creating a custom BVH is on my “maybe-TODO” list, this is actually not required and I did not need it for this article.
In theory
Here’s my algorithm:
- Compute a list of “appropriate” clusters on the GPU. What “appropriate” means in this context will be explained in the “in practice” part.
- Readback this list on the CPU to determine which clusters to create BLASes for.
- Create the corresponding BLASes for these clusters.
- Copy already-prebuilt BLASes inside the newly created BLASes. Or build them if you can’t use precomputed BLASes.
- Create instances of the BLASes for these clusters, which will be put inside the TLAS.
- Build/update the TLAS for the frame.
- Raytrace.
As the title says, this is only the theory. In practice, there are a few points to be careful about, and a few modifications to make to ensure good performance.
In practice
Storing groups
I’m spoiling this article a bit, but for optimisation reasons we will need to store a group index for each meshlet:
struct Meshlet {
std::uint32_t vertexOffset = 0;
std::uint32_t vertexCount = 0;
std::uint32_t indexOffset = 0;
std::uint32_t indexCount = 0;
+ std::uint32_t groupIndex = 0; // used to group meshlets together for raytracing optimisations.
std::uint32_t lod = 0;
Math::Sphere boundingSphere;
Math::Sphere parentBoundingSphere;
// Meshlets form a graph where the root is the most simplified version of the entire model, and each node's children
// are the meshlets which were simplified to create that node.
// Everything is expressed in mesh space here
float parentError = std::numeric_limits<float>::infinity(); // set to infinity if there is no parent (ie the node has no further simplification)
float clusterError = 0.0f;
};
The group index will correspond to the group which this meshlet is part of. Remember that during LOD generation, we needed to group meshlets together before simplification. These groups used to be an intermediate result during simplification, and now they will become the most important part of the algorithm, so let’s store them:
static void appendMeshlets(LoadedPrimitive& primitive, std::span<std::uint32_t> indexBuffer, const Carrot::Math::Sphere& clusterBounds, float clusterError,
+ std::uint32_t* pUniqueGroupIndex
) {
// ... meshlet generation with meshoptimizer
// meshlets are ready, process them in the format used by Carrot:
Carrot::Async::parallelFor(meshletCount, [&](std::size_t index) {
auto& meshoptMeshlet = meshoptMeshlets[index];
auto& carrotMeshlet = primitive.meshlets[meshletOffset + index];
carrotMeshlet.vertexOffset = vertexOffset + meshoptMeshlet.vertex_offset;
carrotMeshlet.vertexCount = meshoptMeshlet.vertex_count;
carrotMeshlet.indexOffset = indexOffset + meshoptMeshlet.triangle_offset;
carrotMeshlet.indexCount = meshoptMeshlet.triangle_count*3;
+ carrotMeshlet.groupIndex = (*pUniqueGroupIndex)++;
carrotMeshlet.boundingSphere = clusterBounds;
carrotMeshlet.clusterError = clusterError;
}, 32);
}
static void generateClusterHierarchy(LoadedPrimitive& primitive, float simplifyScale) {
// very interesting stuff, but already explained in previous articles
std::uint32_t uniqueGroupIndex = 0;
{
// LOD 0
// ...
appendMeshlets(primitive, indexBuffer, lod0Bounds, 0.0f
+ , &uniqueGroupIndex
);
}
// ...
for (int lod = 0; lod < maxLOD; ++lod) {
// ...
for(std::size_t groupIndex = 0; groupIndex < groups.size(); groupIndex++) {
const std::uint32_t currentGroupIndex = uniqueGroupIndex++;
const auto& group = groups[groupIndex];
// ...
// add cluster vertices to this group
// and remove clusters from clusters to merge
for(const auto& meshletIndex : group.meshlets) {
auto& meshlet = previousLevelMeshlets[meshletIndex];
+ meshlet.groupIndex = currentGroupIndex;
// ...
}
// ... simplify group
appendMeshlets(primitive, simplifiedIndexBuffer, simplifiedClusterBounds, meshSpaceError
+ , &uniqueGroupIndex
);
}
}
+ // reindex groups inside glTF to ensure contiguous indices:
+ const std::uint32_t uninitValue = std::numeric_limits<std::uint32_t>::max();
+ Carrot::Vector<std::uint32_t> groupRemap;
+ groupRemap.resize(uniqueGroupIndex);
+ groupRemap.fill(uninitValue);
+ std::uint32_t nextIndex = 0;
+ for(auto& meshlet : primitive.meshlets) {
+ std::uint32_t& remapValue = groupRemap[meshlet.groupIndex];
+ if(remapValue == uninitValue) {
+ remapValue = nextIndex++;
+ }
+ meshlet.groupIndex = remapValue;
+ }
}
Surprisingly, here we increment the group index for each meshlet after generation. We are supposed to group them, so what happened?
The idea is that the leaves of each simplification branch will have their own group index for themselves: meshlets that are not simplified further are considered to be groups of 1 meshlet. Additionally, when creating LOD N+1 from LOD N, inside each group, we give an “actual group index” to the meshlets of LOD N that will be the source for simplification, where this “actual group index” is unique per group. By doing this small dance with group indices, we ensure that meshlets which were grouped together have the same “group index”, and meshlets which are not simplified still have groups that are separate from the rest.
Finally, we remap the group index into contiguous indices, just for easier implementation in runtime. This allows to compute the min / max group indices from meshlets and infer the number of groups. Note that inside the generated glTF, there is only information per meshlet, nothing per group at this point.
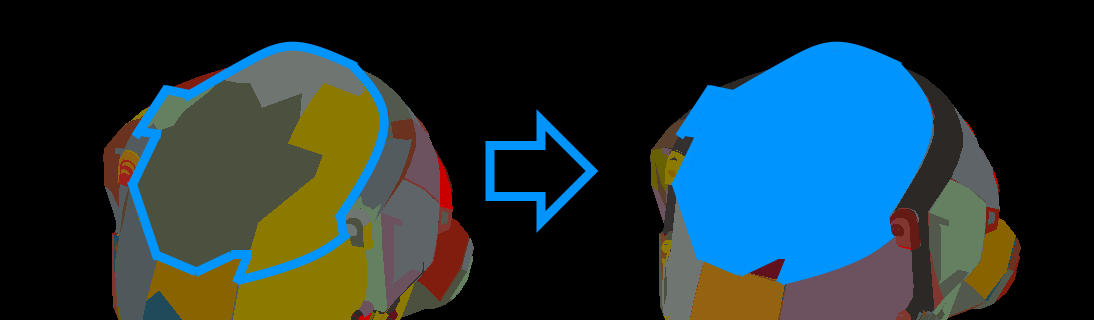
Cluster groups
Precomputing BLASes inside the asset pipeline
Before we go to the runtime code, there is one small thing to add to the asset processing pipeline: precomputing BLASes.
Acceleration structure builds are a bit costly and are also deterministic. It would be a shame to build these structures each time the game is launched. Instead, it is possible to precompute them. One very important information to remember is that the underlying data structures for acceleration structures are driver dependent! Not only are they different from one GPU manufacturer to another, but they may also be different from driver to driver.
Because my engine only runs on my PC for now, I decided to put the acceleration structure generation inside my asset pipeline. I have hopes that different drivers for the same GPU still consider the AS to be compatible, but I don’t have much experience in that domain. However, in the case where precomputing the AS for all GPUs inside the gaming market is not an option for you, it should be possible to replicate what I am about to explain. Nowadays (August 2024), games do not hesitate to have a “Compiling/Optimizing shaders” pass at launch or when starting a level; why not expand this to include AS generation? AS generation is not fast, but it isn’t slow either.
Anyway, that’s a lot of talk for a rather simple process that will be applied on all meshlet groups:
- Have access to the GPU inside your asset pipeline. It wasn’t my case, but sharing the code with my engine would have been painful, so I made a tiny helper.
-
Generate vertex and index buffers representing the group. Here, you are free to do it however you want, either with concatenated buffers and a single geometry, or multiple buffers and multiple geometries. Note that if you use
rayQueryGetIntersectionGeometryIndexEXTor its DXR equivalent to get the geometry index, it is essential that you match what the asset pipeline generates and what your runtime code expects.For example, in my first implementation, I had one geometry per cluster of a group on the runtime side, but one big geometry with concatenated buffers inside the asset pipeline. While this did not outright crash on my GPU, holes would appear in shadows because my rays intersected a triangle at an index which did not exist inside the geometry, completely confusing my lighting shader.
- Compute the size of your AS via vkGetAccelerationStructureBuildSizesKHR
- Allocate the required scratch buffer, create the AS.
- Build the AS via vkCmdBuildAccelerationStructuresKHR.
- (Optional, I don’t do it yet but I should) Compact the AS. This will help with your VRAM usage. Maybe this also helps the performance of copying from memory to acceleration structures? I have not tested that yet.
- Ask for the serialized size with vkCmdWriteAccelerationStructuresPropertiesKHR
- Allocate a buffer of size serialized size, and copy the acceleration structure to it via vkCmdCopyAccelerationStructureToMemoryKHR
- Finally you are able to store this buffer wherever is convenient for you. In my case, I store it inside the glTF generated by my pipeline, in a custom extension.
The serialized structure starts with two UUIDs (32 bytes) which will be used by the driver to tell you whether your precomputed BLAS is compatible with it, more on this later. This is to cover the case where you would build with an NVIDIA GPU but run the game on an AMD GPU for example.
Loading groups
The model file does not contain information about groups directly, so everything has to be recomputed at runtime. This is for easier implementation, and can be changed if needed.
This article is very long so I won’t bore you with all the details, but you can read the implementation here and there.
I advise you to read A basic material pass to understand the difference between cluster templates and cluster instances. Starting with this current article, there can also be group instances that will reference a group template.
Each group instance will get some storage for its raytracing structures, but I’m spoiling the rest of the article again.
Computing the list of appropriate clusters
In this context, “appropriate clusters” means clusters that will look the same in reflections and shadows as they do in the color pass. However, we cannot just reuse the already selected clusters for rasterization: they depend on the camera direction, so we would not be able to see objects that are not visible to the camera:
NSight Graphics capture of TLAS if using clusters visible by camera.
Note that we are missing the scooter, and lots of buildings to the left of the image. We need the list of clusters to be independent from the direction of the camera. Therefore, we need a list that only depends on the camera position.
Luckily, in its current implementation, the selection of clusters made for rasterization has a single dependency on the camera direction: frustum culling. Therefore, the selection code remains the same as for the rasterization case, with the frustum culling removed. Small reminder (but the code is available in a bit further below): the idea is to approximate the size of the bounding sphere of the cluster on screen.
In order to do this, I’ve chosen to add a compute shader before rasterising the visibility buffer, and the role of this compute shader will be to write a list of “appropriate clusters”. While you could create a basic buffer with a list of uint32_t (one per cluster ID) that gets filled by the GPU, I’m going to fill this buffer with cluster group IDs. The performance and memory implications of doing it per cluster will be discussed further down in this article.
In Recreating Nanite: LOD Generation, the simplification algorithm grouped clusters by proximity to prevent seams appearing between clusters. Furthermore, it should be noted that all clusters inside a group make the same LOD decision.
This means that all clusters inside a group will always be “appropriate clusters” at the same time. Therefore we can merge them together from the point-of-view of raytracing, resulting in less memory usage and better performance!
To tell the compute shaders about which groups are currently active (ie. not part of a model that is hidden), I use two buffers:
- Active groups
- Active group offsets
I store the group descriptions inside Active groups: what index it has, and which clusters it contains. Not all groups have the same number of clusters in them, so I need to tell where each group starts inside the buffer, this is where “Active group offsets” becomes useful:
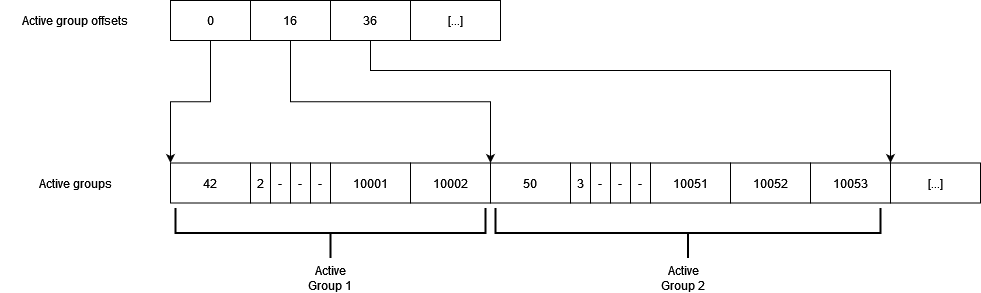
Active group buffers, offsets are in bytes
Finally, the shader checks if one cluster of the group is appropriate, and if so, marks the entire group as “visible”.
#extension GL_EXT_nonuniform_qualifier : enable
#extension GL_EXT_shader_explicit_arithmetic_types_int8 : require
#extension GL_EXT_shader_explicit_arithmetic_types_int16 : require
#extension GL_EXT_shader_explicit_arithmetic_types_int32 : require
#extension GL_EXT_shader_explicit_arithmetic_types_int64 : require
#extension GL_EXT_buffer_reference : require
#extension GL_EXT_buffer_reference2 : require
#extension GL_EXT_scalar_block_layout : require
// ... some includes ...
layout(local_size_x = 32) in;
layout(push_constant) uniform PushConstant {
uint maxGroupID;
// see previous articles
uint lodSelectionMode; // 0= screen size based, 1= force specific LOD
float lodErrorThreshold; // screen size threshold
uint forcedLOD; // lod to force
float screenHeight;
// Active groups data!
uint64_t groupDataAddress;
} push;
// .. cluster data, see previous articles
layout(set = 0, binding = 5, scalar) buffer ActiveGroupOffsets {
uint64_t activeGroupOffsets[];
};
layout(set = 0, binding = 6, scalar) writeonly buffer ReadbackRef {
uint32_t visibleCount;
uint32_t visibleGroupInstanceIndices[];
} readback;
layout(buffer_reference, scalar) buffer ActiveGroup {
uint32_t groupIndex;
uint8_t clusterCount;
// padding seems necessary to access clusterInstances[] properly, even with 'scalar'? Not too sure why it happens
uint8_t pad0;
uint8_t pad1;
uint8_t pad2;
uint32_t clusterInstances[];
};
bool cull(uint clusterInstanceID) {
// Same as for rasterization, with frustum culling removed (see previous article)
}
void main() {
// figure out which group instance we are working on
uint groupIndex = gl_LocalInvocationIndex + gl_WorkGroupID.x * TASK_WORKGROUP_SIZE;
if(groupIndex >= push.maxGroupID) {
return;
}
// find the address of the ActiveGroup struct corresponding to the current group for this thread
ActiveGroup group = ActiveGroup(push.groupDataAddress + activeGroupOffsets[groupIndex]);
// check if any cluster inside the group is appropriate
for(uint clusterIndex = 0; clusterIndex < group.clusterCount; clusterIndex++) {
uint clusterID = group.clusterInstances[clusterIndex];
bool culled = cull(clusterID);
if(!culled) {
// as soon as an appropriate cluster is found, write the group index to the readback buffer, and stop here
// you may note that it is necessary to check only the first cluster, but this is inherited from a previous
// version of the code which had a frustum check
uint readbackIndex = atomicAdd(readback.visibleCount, 1);
readback.visibleGroupInstanceIndices[nonuniformEXT(readbackIndex)] = group.groupIndex;
return;
}
}
}
Compute shader to compute appropriate clusters
And here’s how each buffer is filled each frame (big block of code incoming):
void ClusterManager::render(const Carrot::Render::Context& renderContext) {
// ...
// Will result in a dispatch call
auto& prePassPacket = renderer.makeRenderPacket(PassEnum::PrePassVisibilityBuffer, Render::PacketType::Compute, renderContext);
prePassPacket.pipeline = getPrePassPipeline(renderContext); // gets the pipeline with the compute shader
// ...
BufferView activeGroupsBufferView;
BufferView activeGroupOffsetsBufferView;
// Active group offsets
// Carrot::NoConstructorVectorTraits skips the call to emplace-new for each new element of the vector, not required here because
// 1. the contents are uints
// 2. we override the contents immediately after resizing the vector
Vector<std::uint64_t, Carrot::NoConstructorVectorTraits> activeGroupOffsets { activeInstancesAllocator };
// Active group
Carrot::Vector<std::uint8_t, Carrot::NoConstructorVectorTraits> activeGroupBytes { activeInstancesAllocator };
if(instanceDataGPUVisibleArray) {
ClusterBasedModelData* pModelData = instanceDataGPUVisibleArray->view.map<ClusterBasedModelData>();
// for each model
for(auto& [slot, pModel] : models) {
// if the model is still valid
if(auto pLockedModel = pModel.lock()) {
if(pLockedModel->pViewport != renderContext.pViewport) {
continue;
}
// ...
// Copy the data generated when adding the model to the scene
GroupRTData& rtData = groupRTDataPerModel.at(slot);
const std::size_t offset = activeGroupBytes.size();
activeGroupBytes.ensureReserve(offset + rtData.activeGroupBytes.size());
activeGroupBytes.resize(offset + rtData.activeGroupBytes.size());
memcpy(activeGroupBytes.data() + offset, rtData.activeGroupBytes.data(), rtData.activeGroupBytes.bytes_size());
// Add the groups to the active group offsets buffer, to make sure shader can "see" them
for(const std::uint64_t originalOffset : rtData.activeGroupOffsets) {
activeGroupOffsets.emplaceBack(originalOffset + offset);
}
}
}
// fill single frame buffers with contents of "active groups" and "active group offsets"
activeGroupsBufferView = renderer.getSingleFrameHostBuffer(activeGroupBytes.bytes_size(), GetVulkanDriver().getPhysicalDeviceLimits().minStorageBufferOffsetAlignment);
activeGroupsBufferView.directUpload(std::span<const std::uint8_t>(activeGroupBytes));
activeGroupOffsetsBufferView = renderer.getSingleFrameHostBuffer(activeGroupOffsets.bytes_size(), GetVulkanDriver().getPhysicalDeviceLimits().minStorageBufferOffsetAlignment);
activeGroupOffsetsBufferView.directUpload(std::span<const std::uint64_t>(activeGroupOffsets));
}
// ... some more setup, not important for this article ...
// prepare push constant for shader
{
auto& pushConstant = prePassPacket.addPushConstant("push", vk::ShaderStageFlagBits::eCompute);
struct PushConstantData {
std::uint32_t maxGroupID;
std::uint32_t lodSelectionMode;
float lodErrorThreshold;
std::uint32_t forcedLOD;
float screenHeight;
vk::DeviceAddress groupDataAddress;
};
PushConstantData data{};
data.maxGroupID = activeGroupOffsets.size();
data.lodSelectionMode = lodSelectionMode;
data.lodErrorThreshold = errorThreshold;
data.forcedLOD = globalLOD;
data.screenHeight = renderContext.pViewport->getHeight();
// the shader will directly reinterpret the bytes of the buffer
data.groupDataAddress = activeGroupsBufferView.getDeviceAddress();
pushConstant.setData(std::move(data));
}
const int groupSize = 32;
Render::PacketCommand& prePassDrawCommand = prePassPacket.commands.emplace_back();
prePassDrawCommand.compute.x = activeGroupOffsets.size() / groupSize;
prePassDrawCommand.compute.y = 1;
prePassDrawCommand.compute.z = 1;
renderer.render(prePassPacket);
}
A few notes:
- The nested loops over all models and all groups of each model are a bit costly. The contents of the buffer could be updated only when models are added / removed, but I have opted for simplicity here.
- Active Groups are sent only via a buffer device address, that way the shader can reference any point of the buffer even with variable-length groups.
Readback
Now that the GPU has kindly filled a buffer with the appropriate clusters, it is time to readback from it, and act on it. Note that the buffer is created in CPU-visible and CPU-cached memory, so we can just map it and read from there.
There’s a bit of setup before actually processing the data:
// Disable all RT instances, and delete those who were not used for more than 10s
void ClusterManager::GroupRTData::resetForNewFrame() {
const double currentTime = Time::getCurrentTime(); // time value for start of current frame
constexpr double timeBeforeDelete = 10;
for(auto& rtData : data) {
if(currentTime - rtData.lastUpdateTime >= timeBeforeDelete) {
rtData.as = nullptr;
} else {
if(rtData.as) {
rtData.as->enabled = false;
}
}
}
}
// called by update of ClusterManager
void ClusterManager::queryVisibleGroupsAndActivateRTInstances(std::size_t frameIndex /* index in swapchain (frames in flight)*/) {
// reset state
for(auto& [slot, pModel] : models) {
if(auto pLockedModel = pModel.lock()) {
auto& rtData = groupRTDataPerModel[slot];
rtData.resetForNewFrame();
}
}
for(auto& [pViewport, _] : perViewport) {
// get the readback buffer corresponding to our case
Carrot::Memory::OptionalRef<Carrot::Buffer> ref = getReadbackBuffer(pViewport, frameIndex);
if(!ref.hasValue()) {
continue;
}
// Get CPU pointer to read data from
Carrot::Buffer& readbackBuffer = ref;
const ClusterReadbackData* pData = readbackBuffer.map<const ClusterReadbackData>();
readbackBuffer.invalidateMappedRange(0, VK_WHOLE_SIZE); // make sure CPU can see changes made by GPU (because host cached)
std::size_t count = pData->visibleCount;
// actually process the data
processReadbackData(pViewport, pData->visibleGroupInstanceIndices, count);
}
}
void ClusterManager::processReadbackData(Carrot::Render::Viewport* pViewport, const std::uint32_t* pVisibleInstances, std::size_t count) {
Async::LockGuard l { accessLock }; // make sure no one is trying to add clusters or models while we process the readback buffer
auto& clusterInstances = perViewport[pViewport].gpuClusterInstances;
auto& groupInstances = perViewport[pViewport].groupInstances;
double currentTime = Time::getCurrentTime();
// there is a LOT of data to process, and each group is independent from one another, so do everything in parallel
Async::Counter sync;
std::size_t parallelJobs = 32;
std::size_t granularity = count / parallelJobs;
auto processRange = [&](std::size_t jobIndex) {
GetTaskScheduler().schedule(TaskDescription {
.name = "processSingleClusterReadbackData",
.task = [&, start = jobIndex * granularity](Carrot::TaskHandle& task) {
for(std::size_t i = start; i < start + granularity && i < count; i++) {
processSingleGroupReadbackData(task, pVisibleInstances[i], currentTime, groupInstances, clusterInstances);
}
},
.joiner = &sync, // counter is incremented on task start, and decremented at end
}, TaskScheduler::FrameParallelWork);
};
for(std::size_t jobIndex = 0; jobIndex <= parallelJobs; jobIndex++) {
processRange(jobIndex);
}
// main thread will help while counter is not 0
while(!sync.isIdle()) {
GetTaskScheduler().stealJobAndRun(TaskScheduler::FrameParallelWork);
}
}
Note that I am using the frameIndex of the current frame, this is necessary because I have multiple frames in flight, and the GPU may be still using the memory from the previous frame while computing the current one. This creates a 3 frame latency in what is actually represented in the AS. For a smooth camera movement this should be fine, but for teleportations this may create problems!
Frames in flight, seen in Tracy (old screenshot)
In the Bistro scene, at the position shown in the first image of this article, there are about 11k groups deemed “appropriate”. This is a LOT of groups, so we need to split the work among multiple threads.
Finally, here’s the central piece of the algorithm, creating the BLASes and RT instances for each group:
void ClusterManager::processSingleGroupReadbackData(
Carrot::TaskHandle& task,
std::uint32_t groupInstanceID,
double currentTime,
GroupInstances& groupInstances,
std::span<const ClusterInstance> clusterInstances)
{
const std::uint32_t modelSlot = groupInstances.groups[groupInstanceID].modelSlot;
if(auto pModel = models.find(modelSlot).lock()) {
GroupRTData& groupRTData = groupRTDataPerModel[pModel->getSlot()];
RTData& rtData = groupRTData.data[groupInstanceID - groupRTData.firstGroupInstanceIndex];
rtData.lastUpdateTime = currentTime;
// create BLAS and RT instance (rtData.as) if necessary
if(!rtData.as) {
rtData.as = createGroupInstanceAS(task ,clusterInstances, groupInstances, *pModel, groupInstanceID);
}
// update instance AS transform, model can move
rtData.as->enabled = true;
rtData.as->transform = pModel->instanceData.transform;
}
}
std::shared_ptr<Carrot::InstanceHandle> ClusterManager::createGroupInstanceAS(
TaskHandle& task, // for yields, due to old code, no longer useful
std::span<const ClusterInstance> clusterInstances,
GroupInstances& groupInstances,
const ClusterModel& modelInstance,
std::uint32_t groupInstanceID) {
auto& asBuilder = GetRenderer().getASBuilder();
/* in .h:
struct BLASHolder {
std::shared_ptr<BLASHandle> blas;
// used to have a lock when the code had per-cluster computations
};
*/
BLASHolder& correspondingBLAS = groupInstances.blases[groupInstanceID];
std::shared_ptr<BLASHandle> blas;
{
// if no BLAS exists for this group
// can happen if instance was deleted, but the group is appropriate again
if(!correspondingBLAS.blas) {
const GroupInstance& groupInstance = groupInstances.groups[groupInstanceID];
std::vector<std::shared_ptr<Carrot::Mesh>> meshes;
std::vector<vk::DeviceAddress> transformAddresses;
std::vector<std::uint32_t> materialIndices;
meshes.reserve(groupInstance.group.clusters.size());
transformAddresses.reserve(meshes.capacity());
materialIndices.reserve(meshes.capacity());
for(std::uint32_t clusterInstanceID : groupInstance.group.clusters) {
const ClusterInstance& clusterInstance = clusterInstances[clusterInstanceID];
if(auto pTemplate = geometries.find(templatesFromClusters[clusterInstance.clusterID]).lock()) {
meshes.emplace_back(clusterMeshes[clusterInstance.clusterID]);
transformAddresses.emplace_back(clusterTransforms[clusterInstance.clusterID].address);
materialIndices.emplace_back(clusterInstance.materialIndex);
}
}
if(meshes.empty()) {
return nullptr;
}
// add the BLAS corresponding to this group
// give a precomputed blas to skip building if the precomputed blas is compatible with current GPU and driver
const PrecomputedBLAS* pPrecomputedBLAS = groupInstances.precomputedBLASes[groupInstanceID];
correspondingBLAS.blas = asBuilder.addBottomLevel(meshes, transformAddresses, materialIndices, BLASGeometryFormat::ClusterCompressed, pPrecomputedBLAS);
}
// at this point we have a valid BLAS (at least on engine side, maybe not GPU yet)
blas = correspondingBLAS.blas;
}
// register the group as a new RT instance
return asBuilder.addInstance(blas);
}
We will talk about addBottomLevel and addInstance a bit later, but for now this is just some book-keeping for the engine, to know what will need to be inside BLASes and the TLAS.
BLAS per cluster vs BLAS per cluster-group
You might have noticed that the theory talked about clusters, and here we do everything per group. My first implementation attempted to create a BLAS per cluster and at this point in time, I did not store the group index inside meshlets, so the runtime code had no idea which meshlets could be grouped together.
However, it consumed all my VRAM in that state. With the bistro scene, the code attempted to create 30k BLASes and allocate 4+GB of BLAS objects, so my engine crashed very fast.
The idea of using BLAS groups came into being at this point: less BLASes = less VRAM. At the very beginning of its implementation, I would still compute RT-visibility per cluster, and then figure out which group corresponded to each cluster, and create the data for the group. This required to mess with locks, fiber switches and was much less straight forward than the current implementation - if you can even call it that!
Building vs copying BLASes
Due to the amount of BLASes that can be created in a single frame, it is necessary to optimise their creation time as much as possible.
In this context, I don’t mean only the call to vkCreateAccelerationStructureKHR, but also the calls required to fill the acceleration structure with its data.
With Vulkan, there are two options to create a useable AS:
| Option | Speed | Portable | Batch support |
|---|---|---|---|
vkCmdBuildAccelerationStructuresKHR |
“Slow” | Yes | Yes |
vkCmdCopyMemoryToAccelerationStructureKHR |
Very fast | No, depends on GPU and driver | No 😭 (more on this later) |
However it should be noted that vkCmdBuildAccelerationStructuresKHR requires a call to vkGetAccelerationStructureBuildSizesKHR before, which does NOT have batch support.
Optimizing the first frame
This is now the part on which I spent the most time working.
Preparing the data for raytracing
When a model is loaded, I prepare a buffer with their transform and their meshes used for raytracing. The transforms are used in case the AS still needs to be built, and the meshes are used both for the AS build and for the lighting shader to get vertex attributes.
I do it a model load time to avoid creating hundreds of std::shared_ptr<Carrot::Mesh> during each frame that wants to use new BLASes.
Not the most interesting code, but still helps performance.
// ASBuilder.cpp:
/*static*/ vk::TransformMatrixKHR Carrot::ASBuilder::glmToRTTransformMatrix(const glm::mat4& mat) {
vk::TransformMatrixKHR rtTransform;
for (int column = 0; column < 4; ++column) {
for (int row = 0; row < 3; ++row) {
rtTransform.matrix[row][column] = mat[column][row];
}
}
return rtTransform;
}
// ClusterManager.cpp:
std::shared_ptr<ClustersTemplate> ClusterManager::addGeometry(const ClustersDescription& desc) {
// ...
for(std::size_t i = 0; i < desc.meshlets.size(); i++) {
Meshlet& meshlet = desc.meshlets[i];
Cluster& cluster = gpuClusters[i + firstClusterIndex];
// ...
transforms.emplace_back(ASBuilder::glmToRTTransformMatrix(desc.transform));
// ...
}
// ...
BufferAllocation rtTransformData = GetResourceAllocator().allocateDeviceBuffer(
sizeof(vk::TransformMatrixKHR) * transforms.size(),
vk::BufferUsageFlagBits::eStorageBuffer | vk::BufferUsageFlagBits::eAccelerationStructureBuildInputReadOnlyKHR);
rtTransformData.name(Carrot::sprintf("Virtual geometry transform buffer %llu meshlets", transforms.size()));
rtTransformData.view.stageUpload(std::span<const vk::TransformMatrixKHR>{transforms});
std::size_t vertexOffset = 0;
std::size_t indexOffset = 0;
for(std::size_t i = 0; i < desc.meshlets.size(); i++) {
auto& cluster = gpuClusters[i + firstClusterIndex];
const auto& meshlet = desc.meshlets[i];
cluster.vertexBufferAddress = vertexData.view.getDeviceAddress() + vertexOffset;
cluster.indexBufferAddress = indexData.view.getDeviceAddress() + indexOffset;
clusterTransforms[i + firstClusterIndex].address = rtTransformData.view.getDeviceAddress() + i * sizeof(vk::TransformMatrixKHR);
const Carrot::BufferView vertexBuffer = vertexData.view.subView(vertexOffset, sizeof(ClusterVertex) * meshlet.vertexCount);
const Carrot::BufferView indexBuffer = indexData.view.subView(indexOffset, sizeof(ClusterIndex) * meshlet.indexCount);
// LightMesh only references already existing buffers, and does not create any buffers by itself
clusterMeshes[i + firstClusterIndex] = std::make_shared<LightMesh>(vertexBuffer, indexBuffer, sizeof(ClusterVertex), sizeof(ClusterIndex));
vertexOffset += sizeof(ClusterVertex) * meshlet.vertexCount;
indexOffset += sizeof(ClusterIndex) * meshlet.indexCount;
}
// ...
}
Registering raytracing objects inside Carrot
In the “Readback” section of this article, I kind of glossed over what ASBuilder::addBottomLevel and ASBuilder::addInstance actually do. While I could leave it at “they register some geometry and some instances to be used in raytracing later”, I spent a lot of time trying to improve performance, and I think there are a few interesting things to write about.
If I had to explain broadly what these two functions do, I would say that they are responsible for the AS-book-keeping part of my raytracing pipeline: they tell the engine that some BLASes will need to be built, and return a handle for the rest of the game/engine to use. For example, my model rendering code calls addInstance for each instance of a model, and moves them each frame to match with the rasterized version of the model.
void ModelRenderSystem::renderModels(const Carrot::Render::Context& renderContext) {
parallelForEachEntity([&](Entity& entity, TransformComponent& transform, ModelComponent& modelComp) {
ZoneScopedN("Per entity");
// ... handle visibility
Carrot::InstanceData instanceData;
instanceData.lastFrameTransform = transform.lastFrameGlobalTransform;
instanceData.transform = transform.toTransformMatrix();
instanceData.uuid = entity.getID();
instanceData.color = modelComp.color;
// ... render the model with the info of the current instance
modelComp.modelRenderer->render(modelComp.rendererStorage, renderContext, instanceData, Render::PassEnum::OpaqueGBuffer);
// loads modelComp.tlas (which is a std::shared_ptr<InstanceHandle>)
// calls addInstance internally if necessary
modelComp.loadTLASIfPossible();
if(modelComp.tlas) {
// move raytracing instance (poorly named 'tlas') at the correct place
modelComp.tlas->transform = instanceData.transform;
// update instance color for raytracing-based shading
modelComp.tlas->instanceColor = modelComp.color;
// ...
}
});
}
Once per frame, the engine checks if there are new bottom level geometries and builds their BLAS if needed. Additionally, it updates or rebuilds the TLAS representing the scene based on the new instances.
Before this article, both geometries and instances were stored in what I call “WeakPools”. WeakPools are basically a map from an index (uint32) to a weak_ptr<Something>. I use this in multiple parts of my engine, mostly to handle contiguous arrays of elements referenced by their slot index. For instance, I use this to give textures an ID which is then used to index a global texture array inside shaders. weak_ptr is used to perform some automatic detection of unused elements and reuse slots.
When I started implementing raytracing for virtual geometry, I fought with the problems of such an implementation. The most important one is the need for locking on each access to the map, in order to avoid having two threads use the same ID and try to allocate for the underlying std::unordered_map.
This works fine if all your accesses come from the same thread and you only access the structure a few times at most.
However, with tens of thousands of accesses across 16 threads, you get a LOT of contention. And that’s how you spend 40ms just adding stuff to a map:
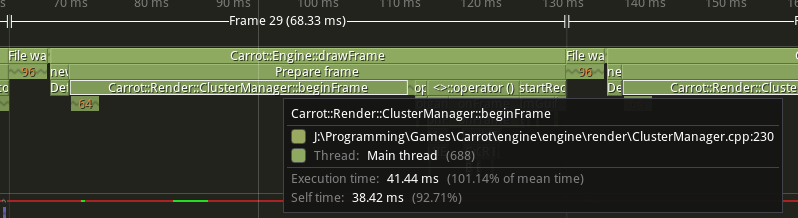
Tracy capture, 41.44ms are spent on the book-keeping part of the raytracing pipeline
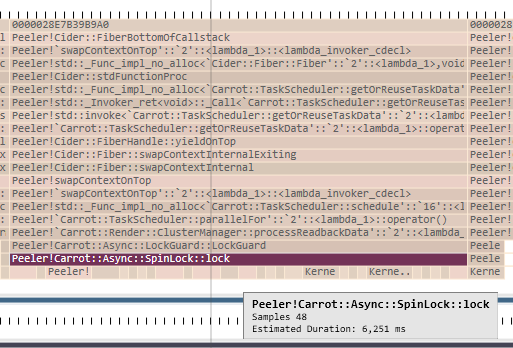
PIX capture, threads spend most of their time waiting on spinlocks
I made multiple attempts before choosing to make a tailored version of this idea for my book-keeping. While at first I separated the selection of slots inside the map and the make_shared call, I soon realized that I could save a lot of time allocating many slots at once, and that I did not need the contiguous aspect of the original implementation (I don’t send these arrays as-is to the GPU).
The idea is simple: you need a read-write lock, an atomic int32, and a sparse array. In this context, my sparse array is a list of “banks” of a fixed size, where bank 1 represents elements with indices Granularity through Granularity*2-1 inside the sparse array. That way, I can allocate the storage for many elements at once, even if they are not already used. Finally, the entire code is as such:
template<typename T>
class ASStorage {
// The storage for 2048 elements will be allocated in one go
constexpr static std::size_t Granularity = 2048;
const std::shared_ptr<T> nullEntry = nullptr;
public:
using Slot = std::unique_ptr<std::weak_ptr<T>>;
using Reservation = std::weak_ptr<T>*;
ASStorage() = default;
/**
* This is the meat of the slot allocation
*/
Reservation reserveSlot() {
// TODO: free list: this implementation does not reuse slots
Async::ReadLock& readLock = rwlock.read();
readLock.lock(); // protect against other threads modifying the 'slots' member
// get the new index
std::uint32_t newID = nextID++;
if(newID < slots.size()) { // inside a bank that was already allocated
// the bank was already allocated so it is safe to access *separate* slots
auto& ptr = slots[newID];
ptr = std::make_unique<std::weak_ptr<T>>(nullEntry);
readLock.unlock();
return ptr.get();
} else {
readLock.unlock();
// need to allocate a new bank
// make sure we are the only thread modifying the structure
Async::WriteLock& writeLock = rwlock.write();
writeLock.lock();
std::size_t requiredSize = (newID / Granularity +1) * Granularity;
if(requiredSize > slots.size()) { // another thread could have come here and already increased the storage size
slots.resize(requiredSize); // create the new banks
}
auto& ptr = slots[newID];
ptr = std::make_unique<std::weak_ptr<T>>(nullEntry);
writeLock.unlock();
return ptr.get();
}
}
private:
mutable Async::ReadWriteLock rwlock;
SparseArray<Slot, Granularity> slots;
std::atomic_int32_t nextID { 0 };
};
Finally, addBottomLevel and addInstance become simple calls to xxxStorage.reserveSlot() with a assignment to the returned weak_ptr.
While this still requires some locking, it is massively amortized over the multiple callers. Making this change transforms the bottleneck from spin locks to… Tracy markers.
Removing the markers yields a 8ms ClusterManager::beginFrame. While this is not perfect, it is much better than 40+ms and should happen only once.
Creating the acceleration structures
Once the engine has decided which BLASes and instances it wants to display, it still has to transfer this information to the GPU, by creating the corresponding acceleration structures.
In order to avoid frames that take multiple seconds, I have two tricks up my sleeve.
The first trick is to allow the creation of only X BLAS per frame (I opted for 1000). Even when “just” copying precomputed acceleration structures, the GPU-side of the operation can get quite long. Indeed the “usual” rendering waits for the BLASes to be fully ready, so it needs to wait for the BLAS copies to finish.
However, with 11k+ BLASes to copy, this can get quite long, and introduces a major delay. This translates to a freeze when raytracing of virtual geometry is enabled:

Frame time history graph, the first frame with raytracing of virtual geometry is very long compared to other frames

Too many BLAS copies per frame can lead to very long frames
Do note that these screenshots were made with the second optimization of this section.
By reducing the maximum amount of BLAS builds per frame, it helps reduce the load of the first frame, which reduces the freeze. Of course, this means the engine needs a few frames to catch up with the entire scene. This is fine for me, this can probably be hidden behind a loading screen; moving the camera in the Bistro at 20m/s stayed below 100 BLAS/frame, which is way less than the 1000 threshold: this should not prevent the render from being correct at this point. For the Bistro scene, it means the raytracing structures are ready in 11 frames when activating the feature. While noticeable, this is a fraction of a second so I think this is good enough for now.
The second trick is to parallelize BLAS builds/copies as much as possible. I start by regrouping BLASes inside 32 buckets. The first 32 entries go into bucket 0, the next 32 into bucket 1, …, and it loops back to bucket 0 starting from BLAS n°1024 (32x32). These buckets allow to batch some operations together, where having a single thread/task per BLAS would introduce too much overhead.
For instance, this restricts the number of command buffers used for builds/copies to a maximum of 32, reducing memory and submit time overhead. Additionally, Tracy supports a maximum of 255 Vulkan contexts, that is enough to avoid this limit and still be able to profile.
Then the build/copy process is executed, in multiple passes:
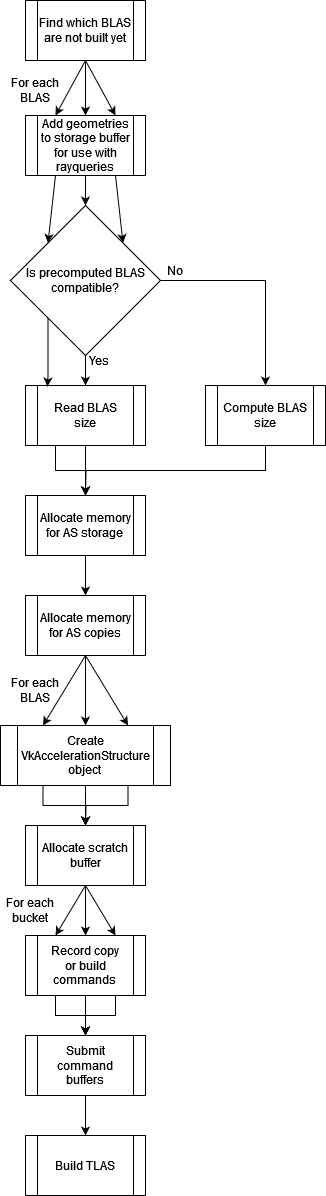
AS build flow
The entire implementation can be found here (you can ignore all the old commented code about compaction, I don’t have compaction at this point of time). The keynotes are:
- Multithreaded command recording: recording a BLAS build or a BLAS copy command is far from free on the CPU, so using multiple threads reduce the wall-time cost.
- Batching allocations: my GPU buffer allocator locks on each allocation, so allocating on each thread introduced a lot of contention, slowing down the build process. In order to mitigate this, I added an option to (sub)allocate multiple buffers at once, locking the allocator only once, reducing contention and improving throughput.
Optimizing the next frames
The frames after the first one to use the readback system can get slow too. Here’s a few tricks I used to make them fast bearable:
- Using VK_BUILD_ACCELERATION_STRUCTURE_PREFER_FAST_TRACE_BIT_KHR is absolutely not negligeable for the TLAS! I think I managed to shave off a few milliseconds from my lighting pass just by adding the flag.
- Batch copies of active IDs: when possible, precompute what is sent to the GPU instead of recomputing it each frame. This may sound obvious, but a memcpy is faster than a for-loop calling pushBack on a vector (even if the memory is already allocated!). The code presented in the articles can still be improved on this point.
- Avoid constructor for uint64 in Vector: my
Vectorimplementation was missing a way to avoid the construction call for trivial types, so I’ve added it. When resizing a vector to add thousands of uints, the constructor call can get quite expensive. As the contents of the vector were overwritten right after theresizecall, there was no point in calling it. This is visible in my code via the use ofCarrot::NoConstructorVectorTraits.
Conclusion
With this article, I have finally managed to make raytracing work with virtual geometry in my engine. By parallelizing some steps, and a few concessions, it is possible to make them work in real time.
I think this was the last thing preventing me from supporting LOD streaming with my virtual geometry implementation, so expect some information on that… soon™. But not too soon, I want to focus on rendering quality first.
Bonus: small rant about Vulkan Acceleration Structures
This is the part where I complain about the current implementation of raytracing and most importantly, acceleration structures in Vulkan. I am not a driver implementer, nor do I know how AS work on the inside, but there are a few things that trouble me.
First, vkCmdBuildAccelerationStructuresKHR takes forever to record if there are many BLASes inside its inputs. I measured about 10ms per call for ~11k BLASes (split among across 32 calls, so ~350 per call).
I can understand that this is not the “usual” way of using raytracing, but still.
It might be possible that vkCmdBuildAccelerationStructuresIndirectKHR fares a bit better. In my use case, if I could move everything to the GPU, I could make the CPU relax a bit and do some other work. However, vkCmdBuildAccelerationStructuresIndirectKHR has no indirect count version, the number of blases needs to be given by the CPU. This mean I still need to go through the CPU to build my BLASes.
Furthermore, vkGetAccelerationStructureBuildSizesKHR has no batch support: each AS needs a separate call to compute the AS size. This is fine until you need to call it thousands of time in a single frame, because (at least on my machine) it keeps stalling threads with code inside the NVIDIA driver. It would be nice if we could provide a buffer of VkAccelerationStructureBuildSizesInfoKHR that would get filled by the command when building multiple AS at once.
Finally, with vkCmdCopyMemoryToAccelerationStructureKHR, I can avoid most of the issues of the build commands. However, there are no batch versions of the copy command, so I need to record a copy call for each AS, which gets slow to record with thousands of AS.