

Recreating Nanite: Mesh shader time
⚠️ This article is a short follow up on Recreating Nanite: Runtime LOD selection. You should read it before reading this article!
Table of contents:
- Introduction
- Support for mesh shaders in Vulkan
- First implementation
- Re-adding LOD selection
- Increasing throughput
- Conclusion
Introduction

Bistro scene rendering via virtual geometry
The implementation of LOD selection in the previous article is done fully on the CPU. While this has the merit to be easy to read and understand, it lacks a critical element to make it useful: performance.
At this point, the CPU has to loop over all loaded clusters, check whether they should be rendered, and output a draw command each frame! Additionnally, this draw command creates a lot of allocations each frame to store cluster data, slowing down the process even more.
Of course, this problem is embarrassingly parallel: each cluster has an independent decision from the others, so this is a place where multithreading could shine. However, you can have tens of thousands of clusters loaded at once, and my poor Ryzen 7 2700X only has 14 threads, so that’s would still be hundreds of clusters to process per thread. Would not it be nice if I could use thousands of threads at once?
Enter: the GPU. You are reading an article on recreating Nanite, of course you knew where this was going.
My first idea was to create a compute shader which would iterate over all active clusters, and output a massive buffer containing all cluster information + an indirect draw command. Of course that would work fine, but I would need to allocate an information buffer accounting for the worst case, and would also need synchronisation between the generation of the buffer and the actual draw call.
Basically I wanted to be able to output “mesh draw commands” based on a more abstract object (here clusters). If you have followed GPU news in the last couple of years, you know there is a shiny new toy for programmers for this exact kind of problem: task and mesh shaders! This is exactly what I chose to reimplement this LOD selection.
In this article, I will progressively extend the implementation to be more and more performant. This represents how I implemented this change, and could represent one way to implement it step by step, without having to refactor everything at once.
Support for mesh shaders in Vulkan
The first step is to enable mesh shader support. Thanksfully, this is rather simple:
- Make sure you are using Vulkan 1.3 (or you will need the NVIDIA mesh shader extension, which is a bit different from the generic one).
- Add
VK_EXT_MESH_SHADER_EXTENSION_NAMEto your device extensions. - Add
VkPhysicalDeviceMeshShaderFeaturesEXTwithtaskShaderandmeshShaderset totrueto yourVkDeviceCreateInfo(viapNext). - Use the stage flag
VK_SHADER_STAGE_MESH_BIT_EXTandVK_SHADER_STAGE_TASK_BIT_EXTfor your mesh and task shaders. - Don’t fill
vertexInput,inputAssembly,vertexBindingDescriptionsandvertexAttributesfor your pipelines using mesh shaders. Mesh shaders require you to create primitives and pull vertices by yourself.
Inside your mesh shader GLSL:
// to be able to use mesh shader functions
#extension GL_EXT_mesh_shader : require
// specifies how many primitives and vertices you output at maximum
// Note that this is per workgroup, not per invocation!
layout(max_vertices=128, max_primitives=128) out;
// specifies your topology, lines are also supported
layout(triangles) out;
void main() {
// ...
// tell how much storage you will actually need
// needs to be < to values inside layout
SetMeshOutputsEXT(vertexCount, triangleCount);
// write vertices
for(int i = 0; i < ...) {
gl_MeshVerticesEXT[i].gl_Position = someTransform * vec4(vertexPosition[i], 1.0);
}
// write triangles
for(int i = 0; i < ...) {
// write indices of triangles
gl_PrimitiveTriangleIndicesEXT[i] = uvec3(index[i * 3 + 0], index[i * 3 + 1], index[i * 3 + 2]);
// write index of triangle
// can be used in fragment shader (optional)
gl_MeshPrimitivesEXT[i].gl_PrimitiveID = i;
}
}
Note: the task shader is optional, and I am first going to present an implementation with only a mesh shader, no task shader.
First implementation: draw everything
I started by drawing all clusters, with no regards for LOD selection nor culling.
This allows to verify that the mesh shading pipeline is working. Additionnally, adding lod selection and culling is basically a single if so it will be easy to add.
I already had a buffer containing all clusters on the GPU, so no need to add it. However, mesh shaders need to know how many vertices a given invocation will output, so I needed to add the vertex count to my cluster structure:
/**
* Sent as-is to the GPU
*/
struct Cluster {
vk::DeviceAddress vertexBufferAddress = (vk::DeviceAddress)-1;
vk::DeviceAddress indexBufferAddress = (vk::DeviceAddress)-1;
std::uint8_t triangleCount;
+ std::uint8_t vertexCount;
std::uint32_t lod;
glm::mat4 transform{ 1.0f };
Math::Sphere boundingSphere{}; // xyz + radius
Math::Sphere parentBoundingSphere{}; // xyz + radius
float error = 0.0f;
float parentError = std::numeric_limits<float>::infinity();
};
Then to modify my graphics pipeline, instead of having a vertex shader, I replaced it by the mesh shader:
{
"type": "gbuffer",
"subpassIndex": 0,
- "vertexFormat": "InstanceDataOnly",
"cull": false,
"alphaBlending": false,
"descriptorSets": [
{
"type": "autofill",
"setID": 0
},
{
"type": "camera",
"setID": 1
- },
- {
- "type": "per_draw",
- "setID": 2
}
],
"depthWrite": true,
"depthTest": true,
- "vertexShader": "resources/shaders/visibility-buffer.vertex.glsl.spv",
+ "meshShader": "resources/shaders/visibility-buffer.mesh.glsl.spv",
"fragmentShader": "resources/shaders/visibility-buffer.fragment.glsl.spv"
}
I also removed the type of vertex format, because this is no longer relevant with mesh shaders.
Finally, it is time to add the actual mesh shader! Let’s go over it step by step:
// preamble: add required extensions
// I use a lot of them for the visibility buffer, but the only important one for this article is "GL_EXT_mesh_shader"
#extension GL_EXT_shader_explicit_arithmetic_types_int8 : require
#extension GL_EXT_shader_explicit_arithmetic_types_int16 : require
#extension GL_EXT_shader_explicit_arithmetic_types_int32 : require
#extension GL_EXT_buffer_reference : require
#extension GL_EXT_buffer_reference2 : require
#extension GL_EXT_scalar_block_layout : require
#extension GL_EXT_mesh_shader : require
// includes for my engine:
#include <includes/camera.glsl>
#include <includes/buffers.glsl>
#include <includes/clusters.glsl>
#include <draw_data.glsl>
DEFINE_CAMERA_SET(1)
Then I setup the bounds of the shader:
// workgroup size will change later in the article, but this keeps things easy
const uint WORKGROUP_SIZE = 1;
layout(local_size_x=WORKGROUP_SIZE) in;
// per workgroup, not per invocation
layout(max_vertices=128, max_primitives=128) out;
layout(triangles) out;
Then the outputs:
layout(location=0) out vec4 outNDCPosition[];
layout(location=1) out flat uint outClusterInstanceID[];
These correspond to the same locations and names that the inputs of the fragment shader:
layout(location = 0) in vec4 ndcPosition;
layout(location = 1) in flat uint instanceID;
Notice how we output multiple values at once in the mesh shader: one per vertex.
Some inputs:
layout(push_constant) uniform PushConstant {
uint maxCluster;
} push;
layout(set = 0, binding = 0, scalar) buffer ClusterRef {
Cluster clusters[];
};
layout(set = 0, binding = 1, scalar) buffer ClusterInstanceRef {
ClusterInstance instances[];
};
layout(set = 0, binding = 2, scalar) buffer ModelDataRef {
InstanceData modelData[];
};
And now, the fun part: creating triangles!
void main() {
uint instanceID = gl_GlobalInvocationID.x;
// bounds check
if(instanceID >= push.maxCluster) {
// tells the GPU we did not output anything
SetMeshOutputsEXT(0,0);
return;
}
#define instance instances[instanceID]
uint clusterID = instance.clusterID;
#define cluster clusters[clusterID]
uint modelDataIndex = instance.instanceDataIndex;
mat4 modelview = cbo.view * modelData[modelDataIndex].transform * clusters[clusterID].transform;
// ...
Once everything is setup, we can actually write vertices and triangles:
void main() {
// ...
// Tell the GPU how many vertices and triangles we *actually* output
SetMeshOutputsEXT(cluster.vertexCount, cluster.triangleCount);
// 1. output vertices
for(uint vertexIndex = 0; vertexIndex < cluster.vertexCount; vertexIndex++) {
// transform the input vertex
const vec4 viewPosition = modelview * cluster.vertices.v[vertexIndex].pos;
const vec4 ndcPosition = cbo.jitteredProjection * viewPosition;
// write the vertex
gl_MeshVerticesEXT[vertexIndex].gl_Position = ndcPosition;
// write some data for the fragment shader
outNDCPosition[vertexIndex] = ndcPosition;
outClusterInstanceID[vertexIndex] = clusterID;
}
// 2. output triangles
for(uint triangleIndex = 0; triangleIndex < cluster.triangleCount; triangleIndex++) {
uvec3 indices = uvec3(cluster.indices.i[triangleIndex * 3 + 0],
cluster.indices.i[triangleIndex * 3 + 1],
cluster.indices.i[triangleIndex * 3 + 2]);
// write the triangle via its indices
gl_PrimitiveTriangleIndicesEXT[triangleIndex] = indices;
// (optional) Write primitive ID to be able to get it back inside fragment shader
gl_MeshPrimitivesEXT[triangleIndex].gl_PrimitiveID = int(triangleIndex);
}
}
Finally, the only thing missing is a draw call:
auto& packet = renderer.makeRenderPacket(PassEnum::VisibilityBuffer, Render::PacketType::Mesh, renderContext);
packet.pipeline = getPipeline(renderContext); //< get your graphics pipeline *somewhere*
// ....
auto& pushConstant = packet.addPushConstant("push", vk::ShaderStageFlagBits::eMeshEXT);
{
// For bounds check inside the shader
std::uint32_t maxID = gpuInstances.size();
pushConstant.setData(std::move(maxID));
}
Render::PacketCommand& drawCommand = packet.commands.emplace_back();
// vvv Total number of clusters vvv
drawCommand.drawMeshTasks.groupCountX = gpuInstances.size();
drawCommand.drawMeshTasks.groupCountY = 1;
drawCommand.drawMeshTasks.groupCountZ = 1;
renderer.render(packet);
// equivalent of:
vkCmdDrawMeshTasksEXT(commandBuffer, gpuInstances.size(), 1, 1);
Notice how the fragment shader did not change! Mesh shaders replace only the Input Assembly -> Vertex Shader -> Hull/Domain/Geometry Shader part of the pipeline, not how fragments are shaded. This means that you could fallback to a regular vertex shader for GPUs that do not support mesh shading, without rewriting the rest of your shaders.
Re-adding LOD selection
This section is a port of the C++ LOD selection to GLSL:
// add new fields to push constant to help lod selection
{
auto& pushConstant = packet.addPushConstant("push", vk::ShaderStageFlagBits::eMeshEXT);
struct PushConstantData {
std::uint32_t maxClusterID;
std::uint32_t lodSelectionMode;
float lodErrorThreshold;
std::uint32_t forcedLOD;
float screenHeight;
};
PushConstantData data{};
data.maxClusterID = gpuInstances.size();
// fixed LOD or automatic LOD?
data.lodSelectionMode = lodSelectionMode;
// error threshold for LOD selection (in pixels)
data.lodErrorThreshold = errorThreshold;
// force to only render a given LOD (for debug)
data.forcedLOD = globalLOD;
// height of screen in pixels
data.screenHeight = renderContext.pViewport->getHeight();
pushConstant.setData(std::move(data));
}
Render::PacketCommand& drawCommand = packet.commands.emplace_back();
drawCommand.drawMeshTasks.groupCountX = gpuInstances.size();
drawCommand.drawMeshTasks.groupCountY = 1;
drawCommand.drawMeshTasks.groupCountZ = 1;
renderer.render(packet);
Inside the mesh shader, we need to check whether we render the cluster or not:
void main() {
// ...
uint modelDataIndex = instance.instanceDataIndex;
mat4 modelview = cbo.view * modelData[modelDataIndex].transform * clusters[clusterID].transform;
+ if(cull(instanceID, clusterID, modelDataIndex, modelview)) {
+ SetMeshOutputsEXT(0,0);
+ return;
+ }
// ...
}
Here’s the implementation of cull:
// assume a fixed resolution and fov
const float testFOV = M_PI_OVER_2;
const float cotHalfFov = 1.0f / tan(testFOV / 2.0f);
vec4 transformSphere(vec4 sphere, mat4 transform) {
vec4 hCenter = vec4(sphere.xyz, 1.0f);
hCenter = transform * hCenter;
const vec3 center = hCenter.xyz / hCenter.w;
return vec4(center, length((transform * vec4(sphere.w, 0, 0, 0)).xyz));
}
// project given transformed (ie in view space) sphere to an error value in pixels
// xyz is center of sphere
// w is radius of sphere
float projectErrorToScreen(vec4 transformedSphere) {
// https://stackoverflow.com/questions/21648630/radius-of-projected-sphere-in-screen-space
if (isinf(transformedSphere.w)) {
return transformedSphere.w;
}
const float d2 = dot(transformedSphere.xyz, transformedSphere.xyz);
const float r = transformedSphere.w;
return push.screenHeight * cotHalfFov * r / sqrt(d2 - r*r);
}
bool cull(uint instanceID, uint clusterID, uint modelDataIndex, mat4 modelview) {
if(push.lodSelectionMode == 0) {
vec4 projectedBounds = vec4(clusters[clusterID].boundingSphere.xyz, max(clusters[clusterID].error, 10e-10f));
projectedBounds = transformSphere(projectedBounds, modelview);
vec4 parentProjectedBounds = vec4(clusters[clusterID].parentBoundingSphere.xyz, max(clusters[clusterID].parentError, 10e-10f));
parentProjectedBounds = transformSphere(parentProjectedBounds, modelview);
const float clusterError = projectErrorToScreen(projectedBounds);
const float parentError = projectErrorToScreen(parentProjectedBounds);
const bool render = clusterError <= push.lodErrorThreshold && parentError > push.lodErrorThreshold;
return !render;
} else {
return clusters[clusterID].lod != uint(push.forcedLOD);
}
}
As I said, same implementation than the C++ version, but in GLSL.
The only thing to note is the SetMeshOutputsEXT(0,0); call and early return if we cull a cluster: that way, we do not output the triangles of a cluster if it is not supposed to be visible.
Earlier cull: Task shaders
At this point, LOD selection is done for each cluster. Because clusters have the same inputs for LOD selection, they will make decisions that fit the entire group (see previous articles). However, I am spawning many mesh shader invocations on the GPU that will not output anything. Furthermore, the role of the mesh shader is to output vertices and triangles for the rasterizer to use.
Therefore, I will now explain how I added task shaders to reduce the complexity of the mesh shader, and to have an architecture which makes more sense (at least to me). This means the code will have the following behaviour:
- CPU: Prepare a draw call with the number of clusters.
- GPU: The task shader will go over all active clusters and determine which ones are culled, and emit mesh tasks for the ones which are not.
- GPU: The mesh shader gets a cluster ID, transform and outputs the vertices and triangles of the corresponding cluster.
First off, let’s remove the LOD selection and culling from the mesh shader:
void main() {
// ...
uint modelDataIndex = instance.instanceDataIndex;
mat4 modelview = cbo.view * modelData[modelDataIndex].transform * clusters[clusterID].transform;
- if(cull(instanceID, clusterID, modelDataIndex, modelview)) {
- SetMeshOutputsEXT(0,0);
- return;
- }
// ...
}
Mesh shader extract
The mesh shader is no longer the “entry point” of your pipeline, so the global invocation index does not mean anything anymore. The task shader will be responsible for sending the proper ID, via the payload:
struct Task
{
uint clusterInstanceID;
};
taskPayloadSharedEXT Task IN;
Mesh shader extract
This payload is available to the entire workgroup emitted by the task shader, but for now I will use a single thread per group to simplify things.
The task shader looks like this:
#extension GL_EXT_mesh_shader : require
// ... includes and extensions
// workgroup size will be changed later in the article
const uint WORKGROUP_SIZE = 1;
layout(local_size_x = WORKGROUP_SIZE) in;
struct Task
{
uint clusterInstanceID;
};
taskPayloadSharedEXT Task OUT;
// ... push constants, inputs and culling code (same as previous section)
void main() {
uint clusterID = gl_GlobalInvocationID.x;
// check if the cluster should be renderered
bool culled = clusterID >= push.maxCluster || cull(clusterID);
// if the cluster should be rendered, output a mesh task to render it
// the clusterID is given to the mesh shader via the task payload (OUT here)
if(!culled) {
OUT.clusterInstanceID = clusterID;
EmitMeshTasksEXT(1, 1, 1);
}
}
Task shader extract
Even more culling: frustum culling
To improve performance even more, the best thing is not to work on useless data: so I added a basic frustum check per cluster to ignore all clusters outside of the area visible by the camera:
float getSignedDistanceToPlane(vec3 planeNormal, float planeDistanceFromOrigin, vec3 point) {
return dot(planeNormal, point) + planeDistanceFromOrigin;
}
bool frustumCheck(in vec4 planes[6], vec3 worldSpacePosition, float radius) {
for(int i = 0; i < 6; i++) {
if(getSignedDistanceToPlane(planes[i].xyz, planes[i].w, worldSpacePosition) < -radius) {
return false;
}
}
return true;
}
// ...
bool cull(uint clusterInstanceID) {
// ...
const mat4 model = modelData[modelDataIndex].instanceData.transform * clusters[clusterID].transform;
const mat4 modelview = cbo.view * model;
// frustum check
{
const vec4 worldSphere = transformSphere(clusters[clusterID].boundingSphere, model);
// frustum check, need groupBounds in world space
// cbo is my camera buffer object
if(!frustumCheck(cbo.frustumPlanes, worldSphere.xyz, worldSphere.w)) {
return true;
}
}
}
Additions to task shader
Increasing throughput
If I stopped here, everything would work, but it would be slooooow.
Just look at this NSight Graphics GPU trace:
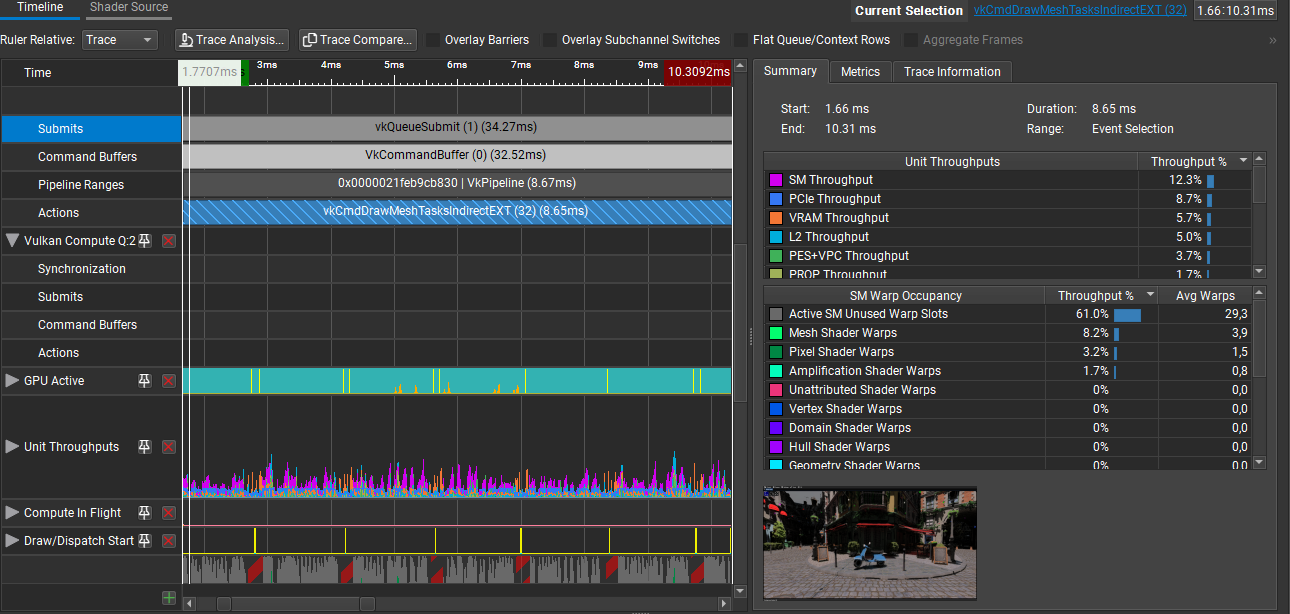
GPU Trace 1 done in NSight Graphics
In this capture, we can see that the drawMeshTasks command takes 8.65ms on the GPU, that’s half a frame just to draw to the visibility buffer!
Note: I am using NSight Graphics because I have a NVIDIA GPU, but of course AMD has a similar tool.
Workgroup size and occupancy
In the capture above, you can see that the Unit Throughputs are very low:
- Mesh shader accounts for 8.2% usage of the GPU
- Fragment shader accounts for 3.2% (called Pixel shader by NSight)
- Task shader accounts for 1.7% (called Amplification shader by NSight)
Most of the time, the GPU is doing basically nothing! I am not an expert at reading these traces, but as I understand it, such low occupancy numbers mean that there are not enough threads working at the same time. Of course, depending on your shader and workload, you may encounter a limit to how high your occupancy can be; but here there is something that can be done.
How to improve occupancy
[…] If your workload generates enough waves, make sure each wave has enough work to do to offset the cost of launching the wave. For compute shaders, try making each wavefront do more work by batching work items together.
“Occupancy explained”, on GPUOpen
Astute readers may notice that the mesh shader already maxes out the amount of work per thread, because there is a single thread per workgroup. However, we are wasting N_threads - 1 threads which do not do anything in the workgroup: in the mesh shader’s case, I needed to use more threads.
The same applies for the task shader, however I was launching one workgroup per cluster, and each workgroup does not have a lot to do.
Long story short: I needed to increase the maximum workgroup size of both mesh and task shaders, in order to have more work done by wavefront.
Let’s start by the mesh shader, which is the easiest to modify.
The key information to notice here is that each vertex is completly independent from all other vertices, and the same goes for indices. In a sense, this is to be expected: that’s exactly how vertex shaders behave.
However, this opens the door to an optimisation: for N vertices, instead of launching 1 thread, we could launch N threads in parallel. This way, each thread works a little bit, but there are less wasted threads. From what I understand, this allows other parts of the pipeline to work earlier (for instance fragment shaders!) so this is worth it.
My idea is to process every X vertex and index inside the shader:
- const uint WORKGROUP_SIZE = 1;
+ const uint WORKGROUP_SIZE = 64; // (actually in an include in my engine, but put here for simplicity)
layout(local_size_x = WORKGROUP_SIZE) in;
void main() {
// ...
+ const mat4 viewProj = cbo.jitteredProjection * modelview;
- for(uint vertexIndex = 0; vertexIndex < cluster.vertexCount; vertexIndex++) {
+ for(uint vertexIndex = gl_LocalInvocationIndex; vertexIndex < cluster.vertexCount; vertexIndex+= WORKGROUP_SIZE) {
- const vec4 viewPosition = modelview * cluster.vertices.v[vertexIndex].pos;
- const vec4 ndcPosition = cbo.jitteredProjection * viewPosition;
// ^ reducing work is also always a good idea (one less matrix mul here)
+ const vec4 ndcPosition = viewProj * cluster.vertices.v[vertexIndex].pos;
// ...
}
- for(uint triangleIndex = 0; triangleIndex < cluster.triangleCount; triangleIndex++) {
+ for(uint triangleIndex = gl_LocalInvocationIndex; triangleIndex < cluster.triangleCount; triangleIndex += WORKGROUP_SIZE) {
// ...
}
}
Modifications to mesh shader
Note the usage of gl_LocalInvocationIndex and WORKGROUP_SIZE.
Modifications for increasing the workgroup size of the task shader are slightly more involved:
// ... extensions and includes
const uint TASK_WORKGROUP_SIZE = 32;
layout(local_size_x = TASK_WORKGROUP_SIZE) in;
struct VisibilityPayload
{
uint clusterInstanceIDs[TASK_WORKGROUP_SIZE];
};
taskPayloadSharedEXT VisibilityPayload OUT;
// ... inputs and culling code, not modified
shared uint meshletCount;
void main() {
if(gl_LocalInvocationIndex == 0) {
meshletCount = 0;
}
barrier();
uint clusterID = activeClusters[gl_LocalInvocationIndex + gl_WorkGroupID.x * TASK_WORKGROUP_SIZE];
bool culled = clusterID >= push.maxCluster || cull(clusterID);
if(!culled) {
uint index = atomicAdd(meshletCount, 1);
OUT.clusterInstanceIDs[index] = clusterID;
}
barrier();
if(gl_LocalInvocationIndex == 0) {
EmitMeshTasksEXT(meshletCount, 1, 1);
}
}
Task shader, modified
The main idea is to write to meshletCount and OUT in parallel where each member of the workgroup will output at most one cluster ID, and increment the meshletCount counter at maximum once.
The payload is shared for the entire workgroup, so only one invocation needs to actually call EmitMeshTasksEXT.
Finally, the mesh shader has to be adapted to use the new payload type:
+ const uint TASK_WORKGROUP_SIZE = 32;
+ struct VisibilityPayload
+ {
+ uint clusterInstanceIDs[TASK_WORKGROUP_SIZE];
+ };
- struct Task
- {
- uint clusterInstanceID;
- };
- taskPayloadSharedEXT Task IN;
+ taskPayloadSharedEXT VisibilityPayload IN;
void main() {
- uint instanceID = IN.clusterInstanceID;
+ uint instanceID = IN.clusterInstanceIDs[gl_WorkGroupID.x % TASK_WORKGROUP_SIZE];
// ...
Modifications to task shader
Indeed, the task shader invokes multiple mesh task groups per task workgroup now (due to the modified EmitMeshTasks call), so each mesh shader has to query the correct cluster ID.
Of course the two workgroup sizes and the payload type can be put in a common included file.
With all this hard work:
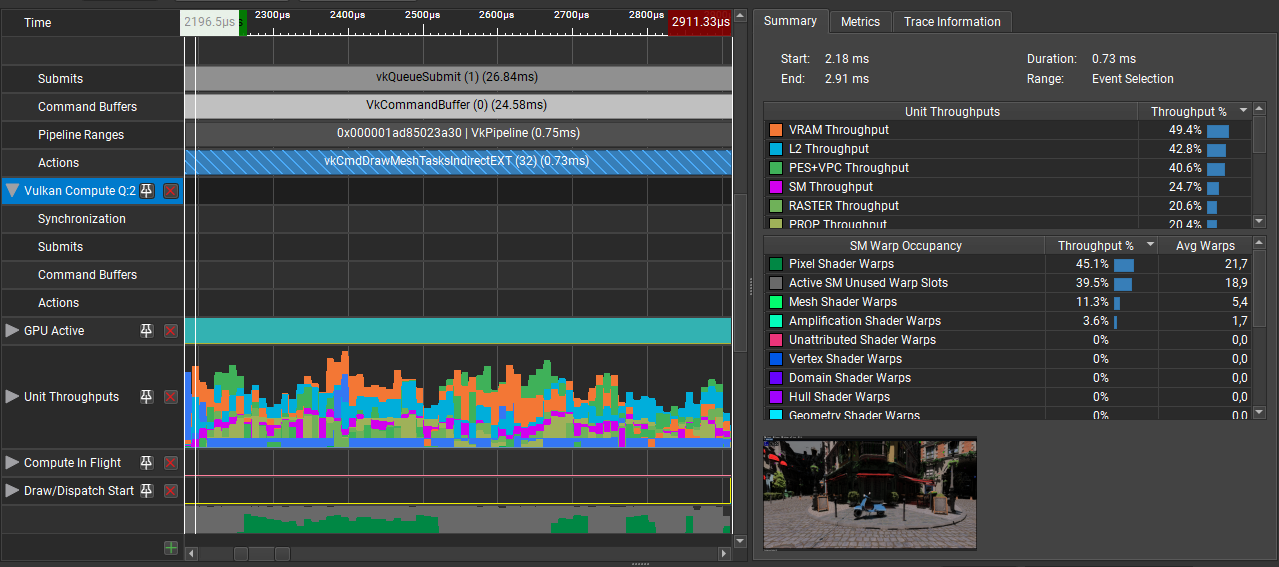
GPU Trace 2 done in NSight Graphics
Look at this happier GPU, it is no longer bored. Mesh shader and task shader occupancy have only slightly increased, but fragment shader occupancy improved by 14x !
And here’s a comparison:
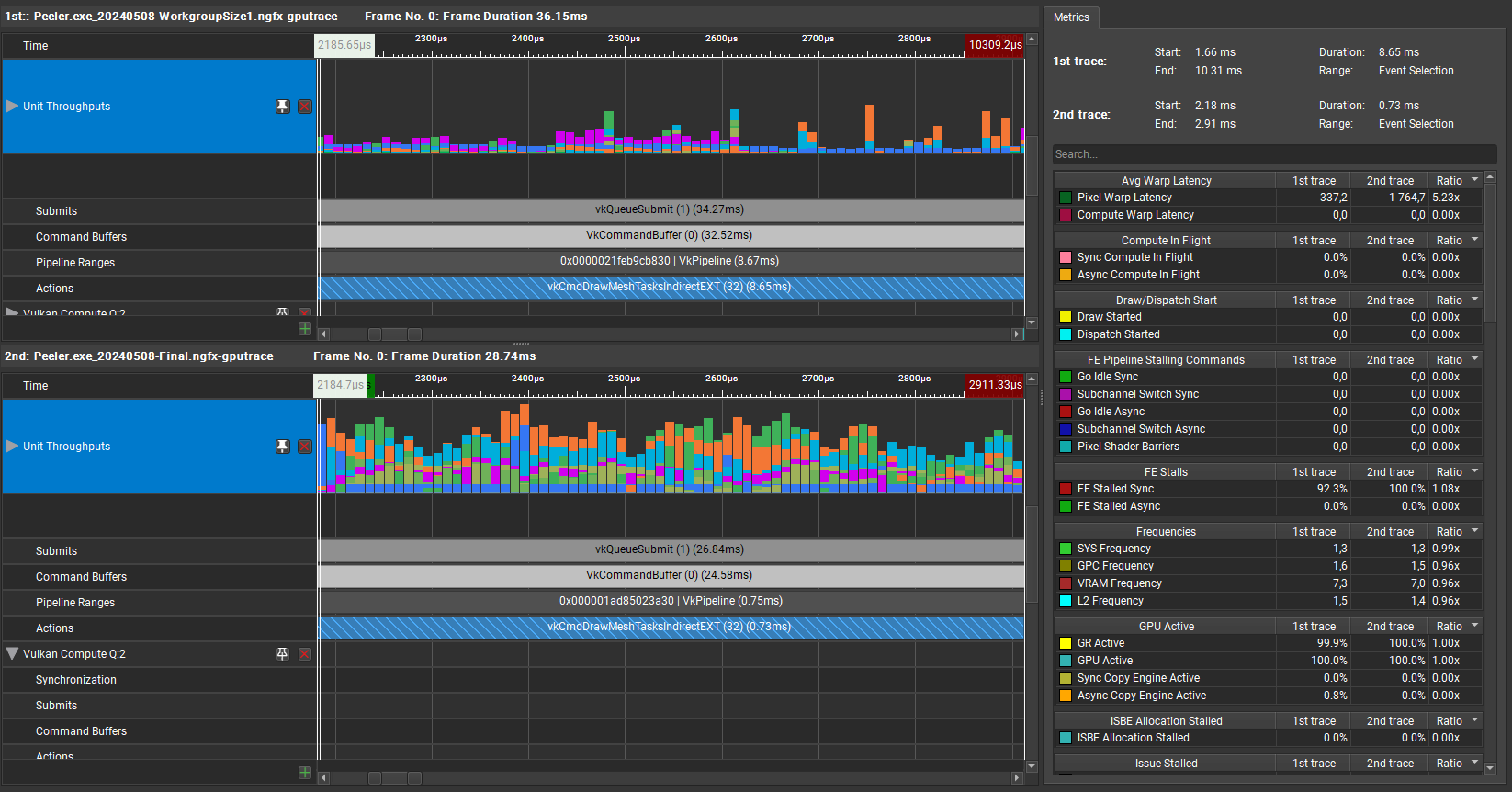
Comparison of GPU Trace 1 and 2
Much better: 8ms is not really feasable for a realtime game, but 0.8ms is way more acceptable!
Small note on atomic usage & feedback buffers
I had a debug output to a buffer to write the displayed triangle count, in order to show it in a debug window, but I had to put it behind a flag.
The GPU capture allowed me to notice that the vkCmdMeshDrawTasksEXT command took way longer than it should. I would love to tell you that thanks to NSight I knew exactly what the problem was, but I am not familiar enough with it so I basically had to try different things. I don’t know if the issue was the write to a CPU-visible buffer, or if it was due to the atomicAdd, or both. However, putting them behind the flag was a major performance improvement.
For reference, here’s what the GPU Trace looks like when the flag is enabled:
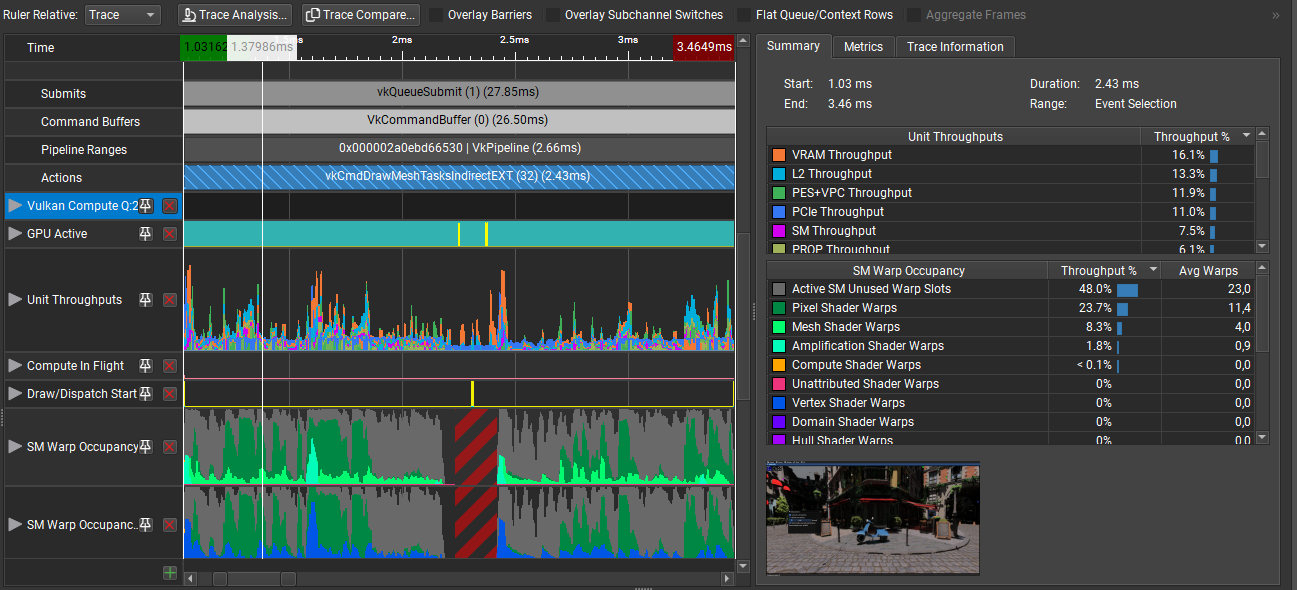
GPU Trace 3: Same as 1 but with debug triangle count enabled
You can notice the performance reduction, and that occupancy crashes down to 0 at the middle of the workload. There is a massive PCIe to BAR Requests increase during this timeframe but I would need to investigate further to know more.
Conclusion
I can now render the Bistro scene at about 80 FPS! I am still GPU bound, but the bottleneck is the lighting + denoising (which do not even look that good currently…).

Bistro scene rendering via virtual geometry, at ~80 FPS
Et voilà!
Related commits:
- Support for mesh shaders
- Move cluster culling / lod selection to mesh shader
- Use task shaders to render cluster-based models
- Add stats buffer to know how many triangles are drawn by mesh shaders for cluster-based models
- Keep separate active clusters list to allow for models to be removed when entities are removed/model components are removed
- Frustum culling for virtual geometry
- Increase workgroup size for virtual geometry task shader