

Recreating Nanite: Cluster rendering
Matching commits:
Table of contents:
- Introduction
- Generating clusters
- Adding a custom extension to glTF
- Preparing and rendering clusters
- What’s next?
Introduction
In the previous article, we stopped after drawing triangles to the visibility buffer. However, after drawing the visibility buffer, we lost the ability to know which mesh a triangle is from.
This means we cannot know the vertex color, nor its UVs, when looking at a given triangle inside the visibility buffer. We could encode a mesh ID inside the buffer. However the goal is to allow for different Level of Detail for different parts of a mesh, so let’s instead encode a cluster ID. A cluster is a small mesh which is made of connected/close triangles of the original mesh.
Graphics API and GPU vendors have worked a lot recently on a technology which is very similar to clusters: mesh shading and meshlets. A meshlet is basically a tiny index buffer, which indexes vertices of an original mesh. The goal is to allow for multiple optimizations, from vertex order, to culling meshlets independently to reduce how many triangles one draws.
The difference I am going to use between meshlets and clusters is that a cluster owns its triangle data, while a meshlet references a pre-existing mesh.
Generating clusters
To this end, I will present to you how to generate meshlets with Meshoptimizer’s mesh shading capabilities.
Meshlets have 4 properties and need 2 two backing storages.
Backing storages:
- Vertex indices: list of indices pointing to the original vertex buffer of your mesh.
- Indices: list of indices to ‘vertex indices’.
Properties:
- Vertex offset: Index of first vertex of the meshlet, inside ‘Vertex indices’.
- Vertex count: How many entries inside ‘vertex indices’ the meshlet spans.
- Index offset: Index of first index of the meshlet, inside ‘Indices’.
- Index count: How many entries inside ‘Indices’ the meshlet spans.
Here’s a small diagram of this organization:

How meshlets represent data. Text in italics represent all the fields available in a single Meshlet instance.
The goal is therefore to generate meshlets after loading a model. For information, here’s the structure I use when loading models:
struct LoadedPrimitive {
std::vector<Carrot::Vertex> vertices;
std::vector<std::uint32_t> indices;
// .. other stuff that we do not really care about for meshlet generation
std::vector<std::uint32_t> meshletVertexIndices; // all vertices of all meshlets (indices of vertices inside original vertex buffer, ie 'vertices' in this struct)
std::vector<std::uint32_t> meshletIndices; // all triangles of all meshlets (indices of vertices inside meshletVertexIndices)
std::vector<Meshlet> meshlets;
};
We will populate meshletVertexIndices, meshletIndices and meshlets based on the contents of vertices and indices, both of which are expected to be filled while loading the model.
The first thing to do is allocate the memory for the meshlets:
static void generateMeshlets(LoadedPrimitive& primitive) {
constexpr std::size_t maxVertices = 64;
constexpr std::size_t maxTriangles = 128;
const float coneWeight = 0.0f; // for occlusion culling, currently unused
auto& indexBuffer = primitive.indices;
const std::size_t maxMeshlets = meshopt_buildMeshletsBound(indexBuffer.size(), maxVertices, maxTriangles);
// prepare memory for meshlets and their indices
std::vector<meshopt_Meshlet> meshoptMeshlets;
primitive.meshlets.resize(maxMeshlets);
meshoptMeshlets.resize(maxMeshlets);
std::vector<unsigned int> meshletVertexIndices;
std::vector<unsigned char> meshletTriangles;
meshletVertexIndices.resize(maxMeshlets * maxVertices);
meshletTriangles.resize(maxMeshlets * maxVertices * 3);
Now we actually generate the meshlets. Meshoptimizer requires a vertex buffer and an index buffer to generate the meshlets.
Spoiler: we will be able to generate meshlets for simplified meshes by varying the index buffer in a later article!
// tell meshoptimizer to generate meshlets
const std::size_t meshletCount = meshopt_buildMeshlets(meshoptMeshlets.data(), meshletVertexIndices.data(), meshletTriangles.data(), // meshlet outputs
indexBuffer.data(), indexBuffer.size(), // original index buffer
(const float*)(primitive.vertices.data()) + offsetof(Carrot::Vertex, pos)/sizeof(float), // pointer to position data
primitive.vertices.size(), // vertex count of original mesh
sizeof(Carrot::Vertex), // stride
maxVertices, maxTriangles, coneWeight);
// resize output buffers based on what was generated
const meshopt_Meshlet& last = meshoptMeshlets[meshletCount - 1];
primitive.meshletVertexIndices.resize(last.vertex_offset + last.vertex_count);
primitive.meshletIndices.resize(last.triangle_offset + ((last.triangle_count * 3 + 3) & ~3));
primitive.meshlets.resize(meshletCount); // remove over-allocated meshlets
And finally we have to massage meshoptimizer’s data into a format ready for the engine. Thanksfully that is pretty easy.
// map meshoptimizer's structures to Carrot's
Carrot::Async::parallelFor(primitive.meshletVertexIndices.size(), [&](std::size_t index) {
primitive.meshletVertexIndices[index] = meshletVertexIndices[index];
}, 1024); // parallel by groups of 1024
Carrot::Async::parallelFor(primitive.meshletIndices.size(), [&](std::size_t index) {
primitive.meshletIndices[index] = meshletTriangles[index];
}, 1024);
// meshlets are ready, process them in the format used by Carrot:
Carrot::Async::parallelFor(meshletCount, [&](std::size_t index) {
auto& meshoptMeshlet = meshoptMeshlets[index];
auto& carrotMeshlet = primitive.meshlets[index];
carrotMeshlet.vertexOffset = meshoptMeshlet.vertex_offset;
carrotMeshlet.vertexCount = meshoptMeshlet.vertex_count;
// offset into 'meshletIndices'
carrotMeshlet.indexOffset = meshoptMeshlet.triangle_offset;
// Carrot stores index count instead of triangle count
carrotMeshlet.indexCount = meshoptMeshlet.triangle_count * 3;
}, 32);
Adding a custom extension to glTF
Saving to glTF
Now we have meshlets, great! However, for performance reasons, we don’t want to build them each time we load a model: we need a way to store them. Carrot uses the glTF format as its primary format for models, and the format can be extended, so let’s add an extension for meshlets!
The extension will be per-primitive, and will contain the indices to accessors for the meshlets data. There are multiple way to present this data, but I have opted for 3 accessors:
- Meshlet data, contains vertex offset, vertex count, index offset, and index count. They are simply memcpy-ed from
Carrot::Render::Meshletto the corresponding buffer. For this article, storing meshlets as 4D vectors of unsigned ints is enough. Later on, we will store unsigned bytes directly, and the buffer view will require the stride to match the size of the struct. - Meshlets vertex indices: a copy of
primitive.meshletVertexIndices, which is just a list ofu32. - Meshlets vertex indices: a copy of
primitive.meshletIndices, which is also just a list ofu32.
Each primitive which has meshlets gets the extension:
"meshes": [
{
"primitives": [
{
"attributes": {
//...
},
//...
"extensions": {
"CARROT_meshlets": {
"meshlets": 5,
"meshlets_indices": 7,
"meshlets_vertex_indices": 6
}
}
}
],
"name": "bunny"
}
],
You can see the code here, but it is basically just filling buffers, nothing fancy.
Reading from glTF
For each primitive, we will need to check whether the extension is present:
static void loadMeshlets(LoadedPrimitive& loadedPrimitive, const tinygltf::Model& model, const tinygltf::Primitive& primitive) {
auto iter = primitive.extensions.find(GLTFLoader::CARROT_MESHLETS_EXTENSION_NAME);
if(iter == primitive.extensions.end()) {
return;
}
If it is present, we get the meshlet accessors for this primitive:
const tinygltf::Value& value = iter->second;
const int meshletsAccessorIndex = value.Get("meshlets").GetNumberAsInt();
const int meshletsVertexIndicesAccessorIndex = value.Get("meshlets_vertex_indices").GetNumberAsInt();
const int meshletsIndicesAccessorIndex = value.Get("meshlets_indices").GetNumberAsInt();
Then, we can start loading meshlets:
{
const tinygltf::Accessor& accessor = model.accessors[meshletsAccessorIndex];
loadedPrimitive.meshlets.resize(accessor.count);
Carrot::Async::parallelFor(loadedPrimitive.meshlets.size(), [&](std::size_t i) {
loadedPrimitive.meshlets[i] = readFromAccessor<Carrot::Render::Meshlet>(i, accessor, model);
}, 16);
}
{
const tinygltf::Accessor& accessor = model.accessors[meshletsVertexIndicesAccessorIndex];
loadedPrimitive.meshletVertexIndices.resize(accessor.count);
Carrot::Async::parallelFor(loadedPrimitive.meshletVertexIndices.size(), [&](std::size_t i) {
loadedPrimitive.meshletVertexIndices[i] = readFromAccessor<std::uint32_t>(i, accessor, model);
}, 16);
}
{
const tinygltf::Accessor& accessor = model.accessors[meshletsIndicesAccessorIndex];
loadedPrimitive.meshletIndices.resize(accessor.count);
Carrot::Async::parallelFor(loadedPrimitive.meshletIndices.size(), [&](std::size_t i) {
loadedPrimitive.meshletIndices[i] = readFromAccessor<std::uint32_t>(i, accessor, model);
}, 16);
}
In case you are curious, here’s the implementation of readFromAccessor:
template<typename T>
static T readFromAccessor(std::size_t index, const tinygltf::Accessor& accessor, const tinygltf::Model& model) {
ZoneScoped; // profiling marker
const tinygltf::BufferView& bufferView = model.bufferViews[accessor.bufferView];
const tinygltf::Buffer& sourceBuffer = model.buffers[bufferView.buffer];
// compute stride based on buffer view stride and if absent, on accessor data type
const std::size_t stride = computeStride(bufferView, accessor);
const void* pSource = sourceBuffer.data.data() + bufferView.byteOffset + accessor.byteOffset + index * stride;
return *((const T*)pSource);
}
And that’s it! Thanksfully, meshlets are easy to represent so they can get serialized to glTF without too much effort.
Preparing and rendering clusters
Now that we can generate, store and read meshlets, the time has finally come to draw them onto the screen!
In the previous article, I used a regular mesh with a vertex buffer and an index buffer to render to the visibility buffer. To avoid binding vertex & index buffers for each cluster, we will instead provide a cluster ID to the vertex shader, and based on this clusterID and the current vertex index, the shader will be able to get the proper vertex, and write the data we want to the visibility buffer. Small note: I needed to support draw commands with no index buffer and no vertex buffer, you might encounter the same issue.
However, we need to provide all this data to the GPU.
Structures
The choice of structures I have made are these (expressed in GLSL):
- The vertex format used by Carrot
// Vertex format used by my engine
struct Vertex {
vec4 pos;
vec3 color;
vec3 normal;
vec4 tangent;
vec2 uv;
};
- Vertex and index buffers. I use
buffer_referenceto be able to provide the device address inside the structure and not have to create a specific descriptor for each cluster. It also simplifies code a lot. I was already using this to access vertices when raytracing hits an object.
// represents a vertex buffer. Stored as vk::DeviceAddress on the CPU-side
layout(buffer_reference, std140) buffer VertexBuffer {
Vertex v[];
};
// represents an index buffer. Stored as vk::DeviceAddress on the CPU-side
layout(buffer_reference, scalar) buffer IndexBuffer {
uint i[];
};
- The cluster, which references its vertices and triangles.
struct Cluster {
VertexBuffer vertices;
IndexBuffer indices;
uint8_t triangleCount;
};
- Finally, we have the buffer with all the clusters, which we will have to fill on the CPU-side. Note the
scalarlayout, we won’t have to worry about padding.
layout(set = 0, binding = 0, scalar) buffer ClusterRef {
Cluster clusters[];
};
Filling the structures
Having these structures is nice and all, but we need to fill them. When loading model that want to use cluster rendering (based on user input in my case), we list all its meshlets, and convert them into clusters. Reminder, I chose the difference to be:
- Meshlets: basically a sub-index buffer into the original mesh
- Clusters: independent from the original mesh, holds its own index and vertex buffers.
Here’s a description of what I do:
- Add as many
Clusterelements as there are meshlets, inside aclustersvector. - Create new vertex & index buffers.
- For each meshlet, copy vertices from the original mesh based on the meshlet’s
vertexIndices,vertexCountandvertexOffset. - For each meshlet, copy indices directly from the meshlet’s
indices.
That way, the index buffer will point to vertices inside the new vertex buffer directly.
- For each meshlet, copy vertices from the original mesh based on the meshlet’s
- Upload these buffers to the GPU (or suballocate them from somewhere)
- Make each cluster point to the buffers, with an offset based on vertex counts and index counts of the cluster (equal to the counts of the corresponding meshlet). Reading the code is easier to understand than reading that sentence.
- Before rendering, upload the
clustersvector to the GPU.
Accessing the structures inside shaders
Once the structures are filled and bound on the GPU, we just need a way to access the cluster ID, and we have everything required to draw the clusters. A few ways of doing this:
- push constants
- per-instance data
- per-drawcall data (if you use indirect-drawing)
I’ve selected to use per-drawcall data: Carrot already supports giving a struct per call to drawIndirect, called “perdraw” data.
It is similar to push constants, but because I manage the buffer and offsets, I can have more memory per drawcall, or reuse the same range.
In my engine, it is usually used to send some data to the GBuffer: the material index and the UUID of the drawn entity (which is a repeat of the per-instance data, so not really used).
In this case, I will encode the cluster ID inside this data. In the version presented in this article, I use the data0 member of the UUID, because it is unused in other contexts.
Here’s how it looks:
// get per-drawcall data
// perDrawDataOffsets is a buffer containing a single u32 ('offset'), with a dynamic offset applied when binding the buffer, to put to the correct value
// yes a push constant would work just as well here
DrawData instanceDrawData = perDrawData.drawData[perDrawDataOffsets.offset + drawID];
// """decode""" cluster ID
uint clusterID = instanceDrawData.uuid0;
Finally, it is just a matter of stringing everything together:
- Find the cluster ID
- Find the vertex index to draw via the index buffer of the cluster
- Access the vertex buffer of the cluster to get the vertex
- Set
gl_Position - Send some information to the fragment shader to draw the cluster.
layout(location = 0) out vec4 ndcPosition;
layout(location = 1) out flat int drawID;
// Vertex format used by my engine
struct Vertex {
vec4 pos;
vec3 color;
vec3 normal;
vec4 tangent;
vec2 uv;
};
// represents a vertex buffer. Stored as vk::DeviceAddress on the CPU-side
layout(buffer_reference, std140) buffer VertexBuffer {
Vertex v[];
};
// represents an index buffer. Stored as vk::DeviceAddress on the CPU-side
layout(buffer_reference, scalar) buffer IndexBuffer {
uint i[];
};
struct Cluster {
VertexBuffer vertices;
IndexBuffer indices;
uint8_t triangleCount;
};
layout(set = 0, binding = 0, scalar) buffer ClusterRef {
Cluster clusters[];
};
// Per instance
layout(location = 0) in vec4 inInstanceColor;
layout(location = 1) in uvec4 inInstanceUUID;
layout(location = 2) in mat4 inInstanceTransform;
layout(location = 0) out vec4 ndcPosition;
layout(location = 1) out flat int drawID;
layout(location = 2) out flat int outClusterID;
void main() {
drawID = gl_DrawID; // draw ID, used to determine which cluster we are drawing
// 1. Find the cluster ID
// find the corresponding cluster index
DrawData instanceDrawData = perDrawData.drawData[perDrawDataOffsets.offset + drawID];
uint clusterID = instanceDrawData.uuid0;
// 2. Find the vertex index to draw via the index buffer of the cluster
// 3. Access the vertex buffer of the cluster to get the vertex
// find the corresponding vertex, gl_VertexIndex is the index of the vertex to draw
// here, we have to find re-index the vertex manually because we don't bind an index buffer
Vertex vertex = clusters[clusterID].vertices.v[clusters[clusterID].indices.i[gl_VertexIndex]];
mat4 modelview = cbo.view * inInstanceTransform;
vec4 viewPosition = modelview * vertex.pos;
ndcPosition = cbo.jitteredProjection * viewPosition;
// 4. Set `gl_Position` and send some information to the fragment shader to draw the triangle.
gl_Position = ndcPosition;
// 5. Send some information to the fragment shader to draw the triangle.
// We just need to send the clusterID
// because gl_PrimitiveIndex will contain the triangle index
// during execution of the fragment shader
outClusterID = int(clusterID);
}
Extract from the vertex shader
The fragment shader stays basically the same:
layout(r64ui, set = 0, binding = 1) uniform u64image2D outputImage;
layout(location = 0) in vec4 ndcPosition;
layout(location = 1) in flat int drawID;
layout(location = 2) in flat int clusterID;
void main() {
ivec2 imageSize = imageSize(outputImage);
vec4 ndc = ndcPosition;
if(ndc.z < 0) {
discard;
}
ndc.xyz /= ndc.w;
vec2 pixelCoordsFloat = (ndc.xy + 1.0) / 2.0 * imageSize;
ivec2 pixelCoords = ivec2(pixelCoordsFloat);
uint depth = 0xFFFFFFFFu - uint(double(ndc.z) * 0xFFFFFFFFu);
// 32 high bits: depth
// 32 low bits: 8 high bits instance ID, 24 remaining: triangle index (will change with cluster rendering)
uint instanceIndex = 0; // TODO: will be done when the material pass is implemented
// TODO: add cluster ID to written value
uint low = ((instanceIndex & 0xFFu) << 24) | (uint(gl_PrimitiveID+1) & 0xFFFFFFu);
// vvv uncomment to draw clusters instead of triangles
//uint low = ((instanceIndex & 0xFFu) << 24) | (uint(clusterID+1) & 0xFFFFFFu);
uint64_t value = pack64(u32vec2(low, depth));
imageAtomicMax(outputImage, pixelCoords, value);
}
Extract from the fragment shader

Final render! Each color spot corresponds to a different cluster: pixels are colored based on the cluster ID instead of the triangle index.
What’s next?
We now have independent clusters. These clusters will allow to write data into the visibility buffer which will allow to fetch vertex information.
However, we still have to find a way to simplify these clusters and create a hierarchy of these clusters, in order to have a hierarchy of clusters with varying LoDs.
Simplification and cluster hierarchy will be the topic of the next article! Here’s a sneak peek:
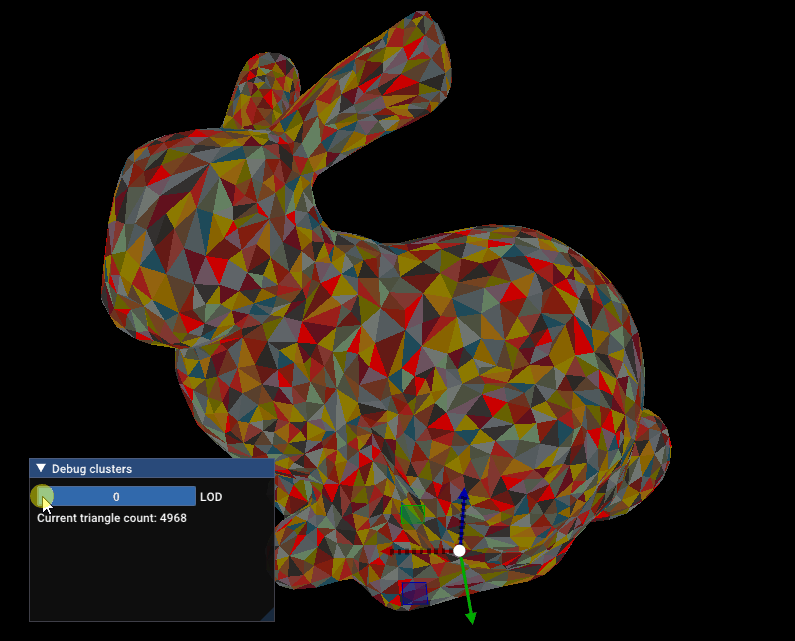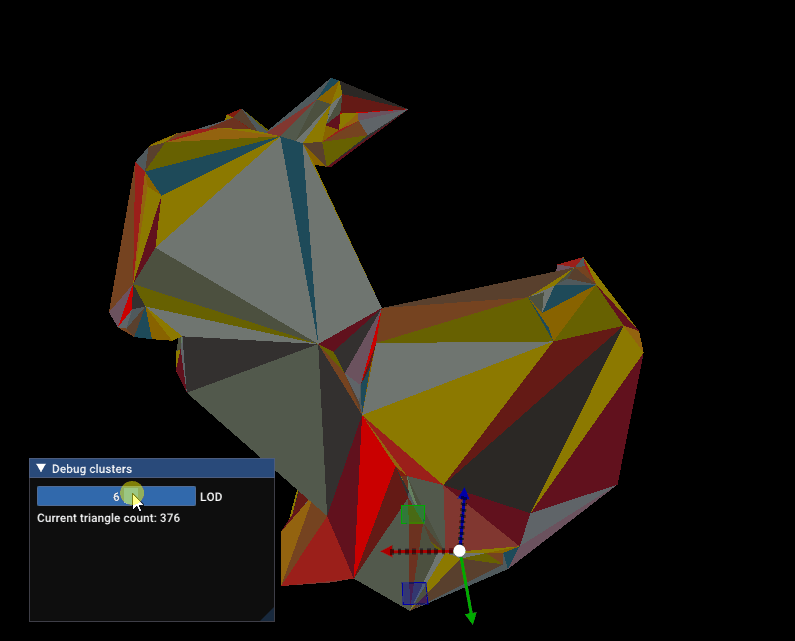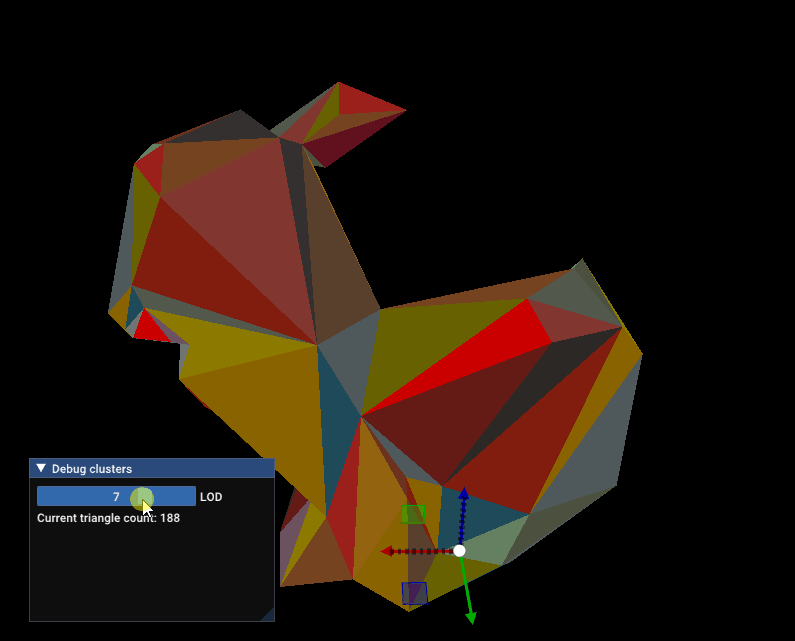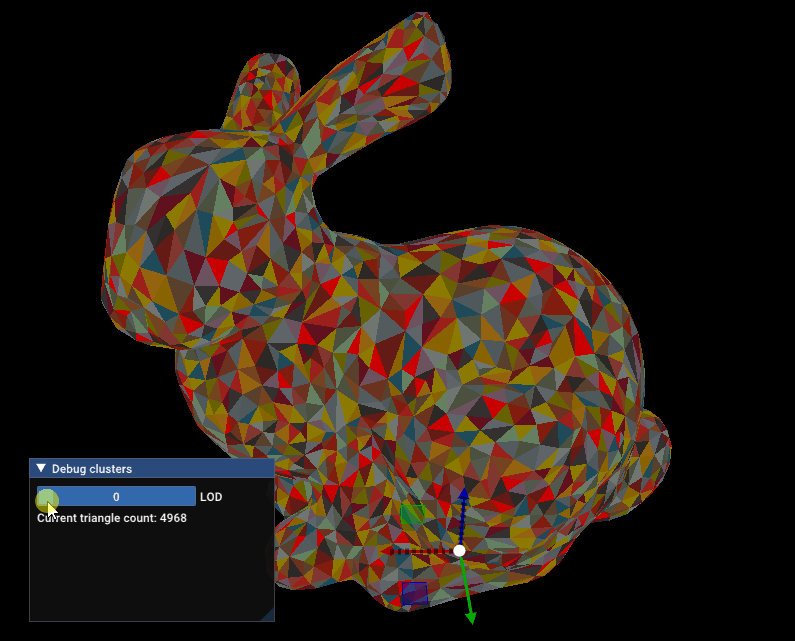
Sneak peek: Standford bunny being simplified